Unit 1. 소프트웨어 교육과 C언어
컴퓨터 과학이 사용되는 범위가 애니메이션, 의학, 패션, 기계공학까지 점점 늘어나고 있고 프로그래밍 활용 분야도 마케팅등 점점 넓어지고 있다. 프로그래밍으로 문제를 해결할 수 있는 부분이 있다면 어느 분야에서든 활용할 수 있다.
1.1 컴퓨터와 프로그램
프로그램은 사람이 원하는 작업을 처리해주는 도구이다. 그러나 기존에 있는 도구로는 원하는 작업을 처리할 수 없을 때 프로그래밍을 통해 직접 문제를 해결하는 프로그램을 만들 수 있다.
1.2 문제 해결을 위한 과학적 사고
복잡한 문제 하나를 해결하기 위해서는 복잡한 문제를 작은 문제들로 작은 문제들을 하나씩 접근하여 해결한다. 다음과 같이 사진을 특수문자로 변환하는 것을 아스키 아트라 한다.

사진을 아스키 아트로 변환하는 것을 작은 문제로 나누어 보면 이미지의 각 픽셀에 대한 정보를 얻어오고, 픽셀의 색상 정보를 얻어오고, 그에 맞는 특수 문자로 출력하는 작은 문제로 나눌 수 있다. 이것처럼 현실 세계의 문제를 분석하여 해결책을 찾는 과학적 사고법을 컴퓨테이셔널 씽킹 이라 하고, 이렇게 설계한 해결책을 컴퓨터 명령어로 작성하는 것을 컴퓨터 프로그래밍이라 한다.
작은 문제로 분해하고, 문제의 패턴을 발견하고, 어떤 데이터를 이용할지 결정하고, 문제를 일반화하고 모델링할 수 있는지를 찾는 과정이다.
아스키 아트로 변환하는 과정을 패턴, 데이터, 일반화와 모델링 과정으로 분류하면 다음과 같다.
- 패턴: 이미지 파일을 읽어서 픽셀의 색상에 따라 특수 문자로 출력
- 데이터: 이미지 파일의 픽셀 데이터, 특수 문자
- 일반화와 모델링: 이미지 파일 읽기, 이미지 파일 분석
1.3 알고리즘과 코딩
파이썬 코딩도장에서 정리한 내용과 동일하다.
studyit312.tistory.com/152?category=454681
[Project H4C] 파이썬 코딩도장(1)
Unit 1. 소프트웨어 교육과 파이썬 1.1 문제 해결을 위한 과학적 사고 전화기, 자동차, 영화산업, 의료 기술, 인공지능 등의 발달로 소프트웨어의 사용 범위는 계속 넓어지고 있다. 그 결과 소프트
studyit312.tistory.com
1.4 C 언어란?
1972년 켄 톰슨과 데니스 리치가 유닉스 운영체제를 만들기 위해 고안한 프로그래밍 언어이다.
켄 톰슨이 BCPL언어를 고쳐 B언어를 개발하였고, 데니스 리치가 B언어를 개선하여 C언어를 개발했다. C언어는 이후의 프로그래밍 언어에 직간접적으로 많은 영향을 주었다.
윈도우, 리눅스, osX등 운영체제의 핵심 요소인 커널도 C언어로 만들어져 있다.
C는 데이터베이스, 가전제품의 컴퓨터, IoT를 만드는데도 사용된다.
메모리와 하드웨어를 직접 제어할 수 있는 언어 이기도 하다.
1.5 코딩도장을 학습하는 방법
파이썬 코딩도장을 통해 학습하는 방법을 알고 있기에 생략한다.
Unit 2. Visual Studio 설치하기
컴파일러로 visual studio code를 사용할 것이고, 설치되어 있기에 생략한다.
Unit 3. Hello, world!로 시작하기
3.1 새 프로젝트 만들기
3.2 프로젝트에 C언어 소스파일 추가하기
다음과 같이 작업공간으로 사용할 폴더를 만들어 hello.c 소스파일을 만들었다.

3.3 Hello, world! 출력하기
소스 파일에 다음과 같이 입력한다.
#include <stdio.h>
int main()
{
printf("Hello world!\n");
return 0;
}Ctrl + F5 키를 누르면 소스파일을 컴파일 하여 실행 파일을 만들 수 있다. 또한 vscode에서 code runner 확장 프로그램을 이용하면 우측 상단의 재생 버튼을 눌러 바로 컴파일 하여 실행할 수 있다.

다음과 같이 터미널에서도 실행 파일을 실행할 수 있다.

위의 소스코드를 보면 printf가 Hello, world!를 출력한다. " "(큰따옴표)로 감싼 부분을 문자열이라 하고, printf()는 화면에 문자열을 출력하는 함수이다. main, printf등 뒤에 괄호가 붙은 단어를 함수라 한다.
printf()괄호 뒤에 ;(세미클론)을 붙이면 printf함수가 실행된다. 함수가 실행되는 것을 함수를 호출(call)한다고 하기도 한다.
Hello, world! 뒤에 붙은 \n은 출력되지 않는다. \n은 제어문자로 화면에 직접 표시되지 않고 문자열을 다음 줄에서 출력되도록 하는 엔터키와 같은 역할을 한다. 파이썬의 print함수는 실행하고 줄바꿈을 하는 것이 기본 설정이라 줄바꿈이 필요 없을 때 따로 지정했어야 했는데 C의 printf함수는 실행하고 줄바꿈을 하지 않아서 줄바꿈을 원하면 \n 제어문자를 넣어야 한다.
소스 코드의 첫줄에 있는 #include는 헤더파일을 포함하는 문법이다. printf 함수를 사용하려면 stdio.h 헤더 파일이 필요하다.
파이썬에서는 소스 파일에 바로 작성하면 됬지만, C의 경우 사용하려는 함수마다 그 함수를 포함하고 있는 헤더파일을 모두 지정해 줘야 한다.
main() 함수는 C로 프로그램을 만들었을 때 프로그램에서 가장 먼저 실행되는 함수이다. 소스에서 main함수가 없다면 컴파일 되지 않기 때문에 main함수는 반드시 있어야 한다.
main 함수의 마지막에 return 0; 이 있다. 함수는 반환값을 함수 바깥으로 전달할 수 있다. main함수도 함수이기 때문에 반환 값을 반환할 수 있다.
3.4 서식지정자 사용하기
서식 지정자는 printf로 문자열을 출력할 때 값으로 바뀌는 부분이다.
#include <stdio.h>
int main()
{
printf("%s\n", "Hello, world!");
return 0;
}
printf함수에 %s를 사용하고 "Hello, world!"를 넣어주면 %s 부분이 "Hello, world!"로 바뀌게 된다.
서식 지정자는 변수를 사용하여 같은 내용을 여러 개 출력하거나, 출력 형태를 바꿀 때 유용하게 사용할 수 있다. 다음과 같이 %s를 여러 번 사용하면 각 %s에 들어갈 문자열을 ,(콤마)로 구분하여 넣으면 된다.
printf("%s %s\n", "Hello", "123");
서식지정자 사이에는 공백이나 여러 문자들이 들어가 서식지정자의 내용과 출력할 문자열을 조합하여 최종 결과를 만들어 낸다.
printf("%s%s\n", "Hello", "123");
printf("%s w%s\n", "Hello", "orld!");
3.5 심사 사이트 이용하기
파이썬 코딩도장을 진행하며 사용해봤기에 생략한다.
3.6 퀴즈

정답은 b이다.

정답은 d이다.

정답은 main이다.

3.7 연습문제: 문자열 출력하기
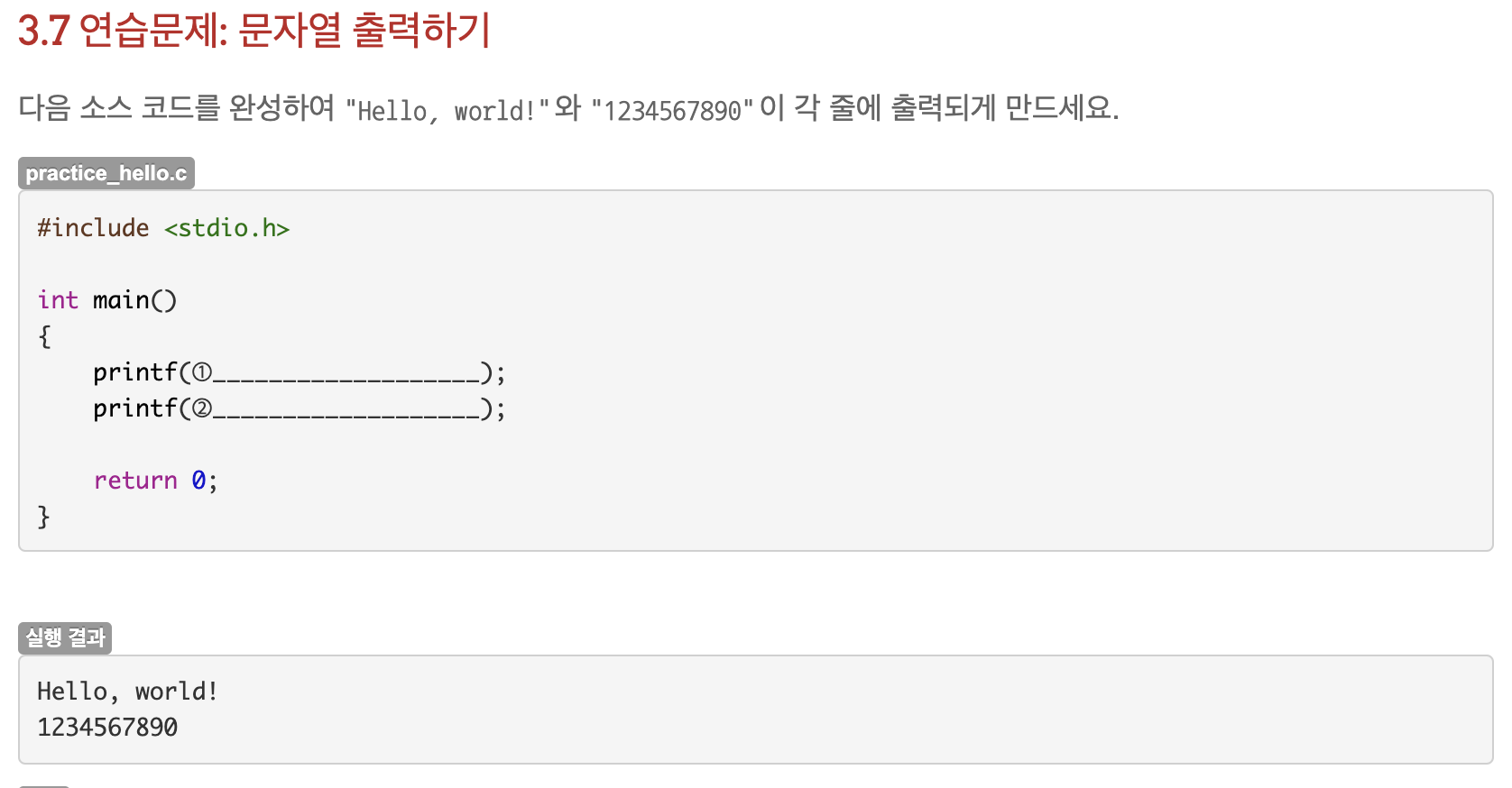
정답은 다음과 같다.
- "Hello, world!\n"
- "1234567890\n"
3.8 연습문제 : 서식지정자 사용하기
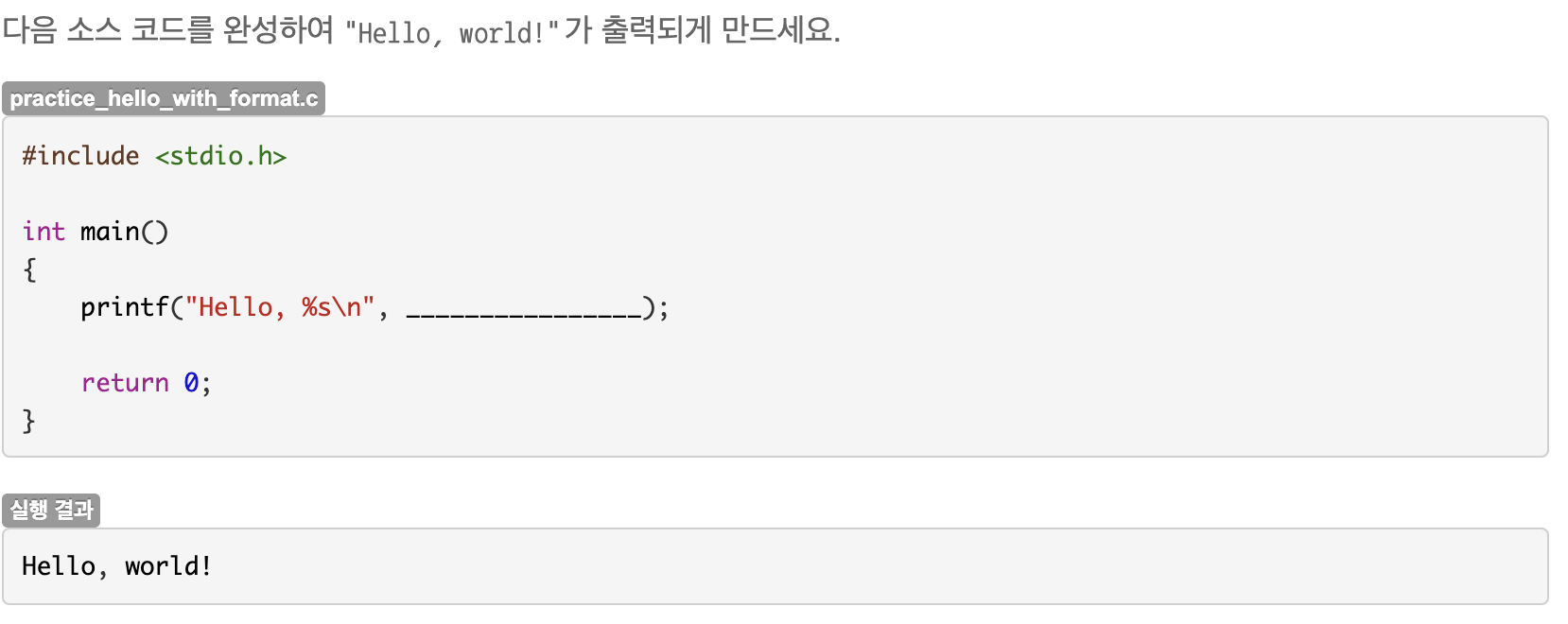
서식지정자 앞에 Hello, 가 있기 때문에 정답은 "world!"이다.
3.9 심사문제 : 문자열 출력하기

제어문자 \n을 이용하여 줄바꿈을 할 수 있으므로 정답은 다음 코드와 같다.
printf("Hello, world!\nHello, world!\n");
3.10 심사문제 : 서식 지정자 사용하기

서식 지정자가 3개 있고, 콤마와 공백이 출력하는 문자열이 있으므로 각 서식문자에는 "Hello", "C", "Language"가 들어가면 된다.
Unit 4. 기본 문법 알아보기
4.1 세미클론
C언어는 구문이 끝날 때 ;(세미클론)을 붙인다. if나 for문등 여러줄로 내용이 계속 이어지는 문법은 세미클론을 붙이지 않는다.
파이썬에서는 구문이 끝나도 세미클론을 붙이지 않아도 됬지만, C언어의 경우 세미클론을 붙이지 않으면 컴파일에러가 발생한다.
4.2 주석
사람만 알아볼 수 있도록 작성하는 부분을 주석이라 한다. 주석은 코드에 대한 자세한 설명을 작성하거나, 특정 코드를 임시로 컴파일 되지 않게 만들 때 사용한다. 파이썬에서 사용한 #을 이용한 주석과 동일한 역할이다.
한줄 주석은 다음과 같이 //을 사용한다. // 뒤에 있는 내용은 코드로 실행되지 않는다.
// 문자열 출력
printf("hello\n"); // hello 출력
// printf("hello world\n");
범위 주석은 다음과 같이 /* 로 시작하며 */ 여러줄을 주석으로 만들 때 사용하며 한줄에서 부분만 주석으로 만들 수 있다.
/*
printf("Hello, world!\n");
printf("1234567890");
*/
printf("Hello" /* 안녕하세요 */);
4.3 중괄호
C에서 중괄호는 코드의 범위를 나타낸다. 다음 코드의 경우 중괄호로 묶인 부분은 main 함수에 소속된 코드이다.
int main()
{
printf("Hello, world!\n");
return 0;
}중괄호는 다음과 같이 if문이나 for문 등의 키워드가 영향을 미치는 영역을 묶을 때도 사용한다.
if (a > 10)
{
printf("a");
}
for (int i = 0; i < 10; i++)
{
printf("Hello, world!\n");
}또한 다음과 같이 구조체(공용체, 열거형)를 정의할 때도 사용한다.
struct Hello {
int a;
int b;
};중괄호 뒤에는 문법에 따라 세미클론을 붙일 때도 있고, 안붙일 때도 있다.
4.4 들여쓰기
C에서는 키워드에 따라 들여쓰기를 사용한다. 보통 {(여는 중괄호)가 시작될 때 들여쓰기를 한다.
다음과 같이 코드가 한 줄이라 중괄호를 생략할 때도 들여쓰기는 하는 것이 코드를 쉽게 알아보기에 좋다.

들여쓰기 방법은 공백 두칸, 4칸, 탭 등 여러 방법이 있다.
들여쓰기 방법은 여러개지만, 다른 사람이 만든 소스코드를 수정할때는 기존의 들여쓰기 규칙을 따르는 것이 좋다.
Unit 5. 변수 만들기
변수는 자료형 뒤에 변수 이름을 선언하는 방식으로 만들 수 있다. 정수를 저장하는 변수를 만드려면 다음과 같이 선언한다.
int num1;int 는 정수를 뜻하는 integer의 축약형이며 변수 이름은 다음의 규칙을 따르고, 원하는 대로 지으면 된다.
- 영문 문자와 숫자를 사용할 수 있습니다.
- 대소문자를 구분합니다.
- 문자부터 시작해야 하며 숫자부터 시작하면 안 됩니다.
- _ (밑줄 문자)로 시작할 수 있습니다.
- C 언어의 키워드(int, short, long, float, void, if, for, while, switch 등)는 사용할 수 없습니다.
변수를 선언하고 맨 뒤에는 반드시 세미클론(;)을 붙여야 한다.
C언어는 파이썬과 달리 변수에 저장할 값에 따라 맞는 자료형을 지정해줘야 한다. C에서 사용할 수 있는 자료형의 종류는 다음과 같다.
- char, short, int, long: 정수(저장할 수 있는 크기가 다릅니다)
- float, double: 실수
- void: 형태가 없는 자료형(포인터를 사용할 때, 함수의 반환값을 표현할 때 등 다양하게 사용됩니다)
5.1 변수를 만들고 값 저장하기
#include <stdio.h>
int main()
{
int num1; // 정수형 변수 선언
int num2;
int num3;
num1 = 10; // 변수에 값 할당
num2 = 20;
num3 = 30;
printf("%d %d %d\n", num1, num2, num3); // 변수에 저장한 값을 %d 로 출력
return 0;
}
변수에 값을 할당(저장)할 때는 =(등호)를 사용한다. 변수에 값을 할당하고 출력할 때는 %d 서식지정자를 사용한다. %d는 10진수를 출력할 때 사용하는 서식지정자 이다. 서식지정자 %d에 각 변수가 대응되어 3개의 변수에 저장된 3개의 값이 출력되었다.
5.2 변수 여러 개를 한 번에 선언하기
#include <stdio.h>
int main()
{
int num1, num2, num3; // 변수를 콤마로 구분하여 여러개를 선언
num1 = 10; // 변수에 값 할당
num2 = 20;
num3 = 30;
printf("%d %d %d\n", num1, num2, num3); // 변수에 저장한 값을 %d 로 출력
return 0;
}
위 코드와 같이 int를 한 번만 사용한 뒤 변수를 콤마로 구분하여 여러개의 변수를 선언할 수 있다. 자료형이 같을 때만 가능하며, 자료형이 다르다면 따로 선언해야 한다.
5.3 변수를 선언하면서 초기화하기
#include <stdio.h>
int main()
{
int num1 = 10; // 변수를 선언하면서 값 할당(초기화)
int num2 = 20, num3 =30; // 변수 여러 개를 선언하면서 값 할당(초기화)
printf("%d %d %d\n", num1, num2, num3); // 변수에 저장한 값을 %d 로 출력
return 0;
}
위 코드처럼 변수를 선언하면서 =로 값을 할당하여 초기화 할 수 있다. 또한 변수 여러개를 선언하면서 값을 초기화 할 수 도 있다. 각 코드의 마지막에는 반드시 세미클론을 붙여야 한다.
5.4 퀴즈

정답은 c이다.

정답은 c, e, f, h 이다.

정답은 d이다.

정답은 b이다.
5.5 연습문제 : 변수 여러 개를 선언하면서 값 초기화 하기

변수 이름 num1, num2, num3 각각에 값 10, 20, 30을 할당해야 하므로 정답은 다음 코드와 같다.
int num1 = 10, num2 = 20, num3 = 30;
5.6 심사문제 : 변수를 선언하고 값 할당하기

num1 변수는 선언되어 있기 때문에 정답은 다음 코드와 같다.
num1 = 10;
int num2 = 20, num3 = 30;
Unit 6. 디버거 사용하기
버그는 프로그램이 의도치 않은 동작을 일으키는 것을 말한다. 디버거는 버그를 제거하는 도구 라는 뜻으로 프로그램의 내부 상황을 쉽게 파악할 수 있어 버그(문제점)를 찾는데 도움을 준다.
6.1 중단점 사용하기
중단점은 브레이크 포인트(Break point)라고도 부르는데, 소스코드의 특정 지점에서 프로그램의 실행을 멈추는데 사용한다. 소스코드는 다음 코드를 사용한다.
#include <stdio.h>
int main()
{
int num1 = 10; // 변수를 선언하면서 값 할당(초기화)
int num2 = 20, num3 =30; // 변수 여러 개를 선언하면서 값 할당(초기화)
printf("%d %d %d\n", num1, num2, num3); // 변수에 저장한 값을 %d 로 출력
printf("%d\n", num2);
return 0;
}{ (여는 중괄호)가 있는 줄의 줄 번호 왼쪽을 클릭하면 빨간 원이 생긴다.

빨간색 원은 중단점을 의미하며 이곳에서 실행을 멈추라는 의미이다.
중단점을 삽입하고, F5 키를 눌러서 디버깅을 시작한다.
그러면 노란색 화살표에 빨간 원이 들어가며 그 줄에서 프로그램이 중단된다.

4번째 줄까지 실행 했고 5번째 줄을 실행할 차례라는 의미이다. 코드를 한줄 한줄 실행할 때는 F10 키를 누르면 된다. F10을 누르면 노란색이 한 줄씩 내려가면서 코드가 한줄 한줄 실행된다.
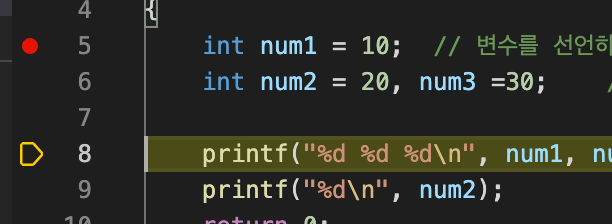
지금 상태는 num1, num2, num3 변수가 선언되며 값이 할당되고, 아직 출력은 하지 않은 상태이다. 지금 상태에서 DEBUG CONSOLE을 확인해보면 아무것도 출력되지 않는다.

여기서 F10을 한번 더 누르면 8번째 줄이 실행되여 3개의 변수가 출력된다.

한번 더 F10을 누르면 다음줄도 실행된다.


디버깅을 끝내려면 Shift + F5를 누르면 된다.
Visual Studio Code의 디버거 단축키는 다음과 같다.
- 중단점 삽입/삭제: F9
- 디버깅 시작: F5
- 디버깅 중지: Shift+F5
- 프로시저 단위 실행: F10
- 한 단계씩 코드 실행: F11
- 함수 안으로 들어갈 때 사용하는 단축키이다.
Unit 7. 정수 자료형 사용하기
정수 자료형은 크게 char과 int가 있고, 앞에 부호 키워드(signed, unsigned)와 크기 키워드(short, long)을 붙여서 특성을 정의할 수 있다.
signed는 부호가 있는 정수를 표현하며 보통 생략한다. unsigned는 부호가 없는 정수를 표현하여 값은 0부터 시작한다.
C에서는 정수 자료형이 char ,int에 여러 키워드를 조합하여 여러가지가 있지만, 파이썬의 정수 자료형은 int 하나이다.
다음은 정수 자료형 키워드를 조합했을 때 자료형의 크기와 저장할 수 있는 값의 범위이다.
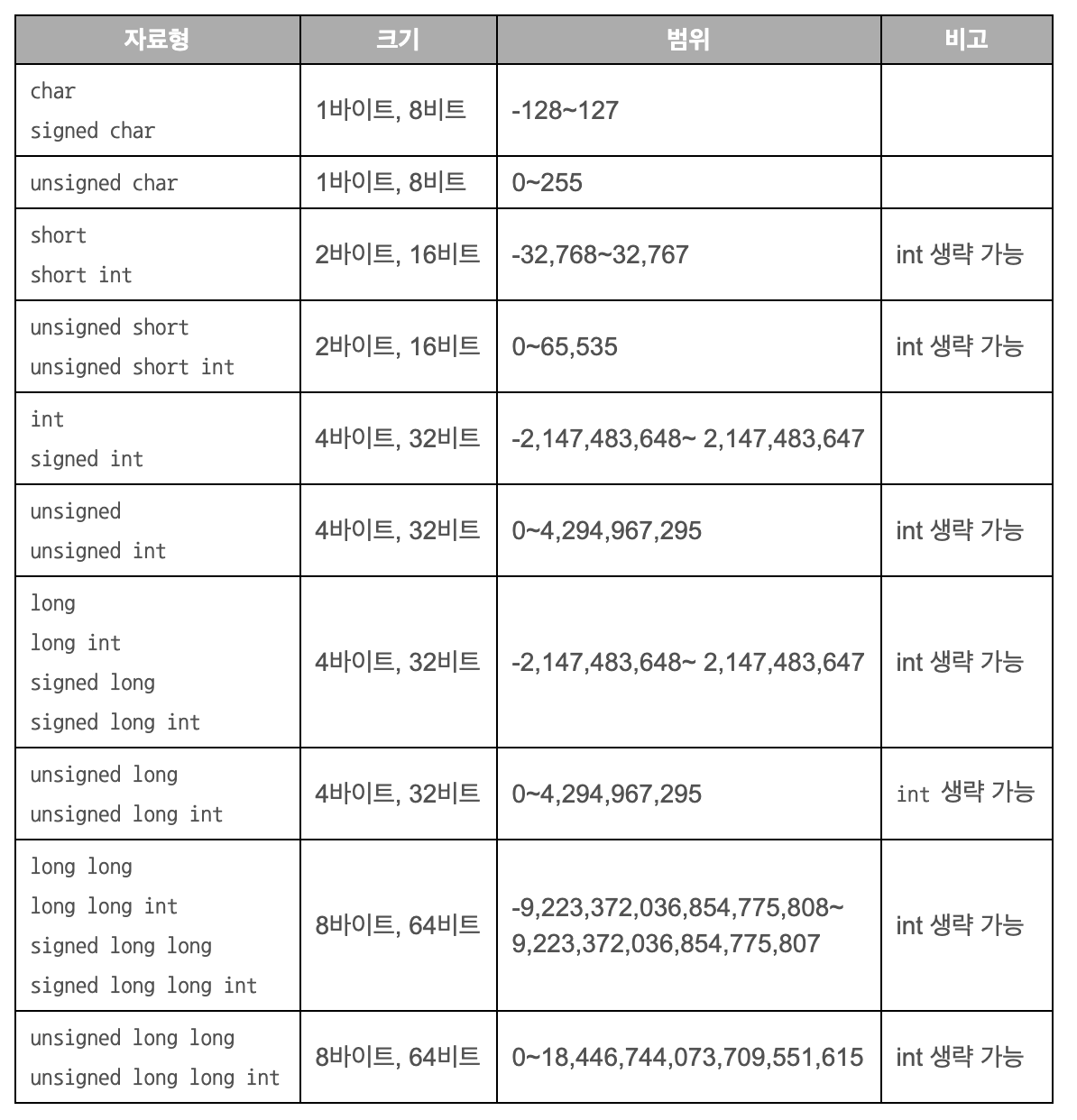
정수 자료형의 크기와 범위를 그림으로 표현하면 다음과 같다. signed와 unsigned는 범위가 다를 뿐 크기는 같다.

7.1 정수형 변수 선언하기
#include <stdio.h>
int main()
{
char num1 = -10; // 1바이트 부호 있는 정수
short num2 = 30000; // 2바이트 부호 있는 정수
int num3 = -1234567890; // 4바이트 부호 있는 정수
long num4 = 1234567890; // 4바이트 부호 있는 정수
long long num5 = -1234567890123456789; // 8바이트 부호 있는 정수
printf("%d %d %d %ld %lld\n", num1, num2, num3, num4, num5);
return 0;
}
위 코드는 부호있는 정수를 만들어 값을 할당한 것이다. 부호있는 정수는 보통 signed를 생략한다. short 와 long은 int 를 생략한다. char은 character의 약어로 문자를 뜻하지만 기본적으로는 정수형이다.
printf함수에서 char, short, int는 %d 서식지정자를 사용하지만 long는 %ld, long long는 %lld 서식지정자를 사용한다.
부호 없는 정수 자료형은 다음과 같다.
#include <stdio.h>
int main()
{
unsigned char num1 = 200; // 1바이트 부호 없는 정수
unsigned short num2 = 60000; // 2바이트 부호 없는 정수
unsigned int num3 = 4123456789; // 4바이트 부호 없는 정수
unsigned long num4 = 4123456789; // 4바이트 부호 없는 정수
unsigned long long num5 = 12345678901234567890; // 8바이트 부호 없는 정수
printf("%u %u %u %lu %llu\n", num1, num2, num3, num4, num5);
return 0;
}
부호 없는 정수 자료형은 앞에 unsigned 키워드를 붙여주면 된다.
printf함수에서 서식지정자로 %d를 사용해도 되지만, unsigned키워드가 붙은 정수는 %u, %lu, %llu를 이용하여 출력해야 한다.
7.2 오버플로우와 언더플로우 알아보기
#include <stdio.h>
int main()
{
char num1 = 128;
unsigned char num2 = 256;
printf("%d %u\n", num1, num2);
return 0;
}
num1 은 char 자료형 범위의 최대값인 127 보다 큰 128을 저장했고, num2는 unsigned char 자료형 범위의 최대값인 255보다 큰 256을 저장했다. 실제 출력에서는 -128과 0이 나왔다. 저장할 수 있는 최대값의 범위를 넘어서서 오버플로우가 발생하여 다시 최솟값부터 시작하게 되므로 -128과 0이 나오는 것이다. 다른 자료형들도 저장할 수 있는 최대값의 범위를 넘어서면 오버플로우가 발생해 최솟값부터 다시 시작한다.
반대로 저장할 수 있는 최솟값보다 작은 값을 저장하면 언더플로우가 발생하여 최댓값에서 다시 시작하게 된다.

파이썬에서는 int 자료형이 숫자의 범위를 제한하고 있지 않아서 오버플로우가 발생하지 않을 것이다.
7.3 자료형 크기 구하기
자료형의 크기를 바이트 단위로 구할 때는 sizeof 연산자를 사용한다. sizeof 연산자는 다음과 같은 형식으로 사용한다.
- sizeof 표현식
- sizeof(자료형)
- sizeof(표현식)
#include <stdio.h>
int main()
{
int num1 = 0;
int size;
size = sizeof num1;
printf("num1의 크기 : %d\n", size);
return 0;
}
변수 num1의 자료형 크기를 구한 것이다. 표현식은 변수, 상수, 배열 등 프로그래머가 만들어낸 요소를 뜻한다. 정수 int형 변수 num1의 자료형을 구했기 때문에 4가 출력됬다.
다음과 같이 sizeof(자료형)의 방식과 sizeof(표현식)의 방식으로도 사용할 수 있다.
int size1;
int size2;
int num1 = 0;
size1 = sizeof(int);
size2 = sizeof(num1);각 정수 자료형의 크기를 구해보면 다음과 같다.
#include <stdio.h>
int main()
{
printf("char : %d, short : %d, int : %d, long : %d, long long : %d\n",
sizeof(char),
sizeof(short),
sizeof(int),
sizeof(long),
sizeof(long long)
);
return 0;
}
char는 1바이트, short는 2바이트, int와 long은 4바이트, long long은 8바이트이다.
7.4 최솟값과 최댓값 표현하기
소스코드에서 정수의 최솟값을 표현하려면 limits.h 헤더 파일을 사용해야 한다. limits.h는 자료형의 최솟값과 최댓값이 정의된 헤더파일이다.
#include <stdio.h>
#include <limits.h>
int main()
{
char num1 = CHAR_MIN; // char 최솟값
short num2 = SHRT_MIN; // short 최솟값
int num3 = INT_MIN; // int 최솟값
long num4 = LONG_MIN; // long 최솟값
long long num5 = LLONG_MIN; // long long 최솟값
printf("%d %d %d %ld %lld\n", num1, num2, num3, num4, num5);
return 0;
}
limits.h 파일에는 다음과 같이 정수 자료형들의 최솟값과 최댓값이 정의되어 있다.

다음과 같이 limits.h에 정의된 최댓값을 넘어서도 오버플로우가 발생하여 최솟값부터 다시 시작하며, 최솟값보다 작아지면 언더플로우가 발생하여 최댓값이 출력되게 된다.
#include <stdio.h>
#include <limits.h>
int main()
{
// 부호 있는 정수 오버플로우
char num1 = CHAR_MAX + 1;
short num2 = SHRT_MAX + 1;
int num3 = INT_MAX + 1;
long long num4 = LLONG_MAX + 1;
printf("%d %d %d %lld\n", num1, num2, num3, num4);
// 부호 없는 정수 오버플로우
unsigned char num5 = UCHAR_MAX + 1;
unsigned short num6 = USHRT_MAX + 1;
unsigned int num7 = UINT_MAX + 1;
unsigned long long num8 = ULLONG_MAX +1;
printf("%u %u %u %llu\n", num5, num6, num7, num8);
// 부호 있는 정수 언더플로우
char num9 = CHAR_MIN - 1;
short num10 = SHRT_MIN - 1;
int num11 = INT_MIN - 1;
long long num12 = LLONG_MIN - 1;
printf("%d %d %d %lld\n", num9, num10, num11, num12);
// 부호 없는 정수 언더플로우
unsigned char num13 = 0 - 1;
unsigned short num14 = 0 - 1;
unsigned int num15 = 0 - 1;
unsigned long long num16 = 0 - 1;
printf("%u %u %u %llu\n", num13, num14, num15, num16);
return 0;
}
값을 계산하다가 오버플로우 또는 언더플로우 현상이 발생할 경우 의도치 않은 결과가 나올 수 있기 때문에 프로그래밍 할 때는 값의 범위를 항상 주의해야 한다.
7.5 크기가 표시된 정수 자료형 사용하기
C99 표준부터 stdint.h 헤더 파일이 추가되면서 크기가 표시된 정수 자료형을 사용할 수 있게 되었다.
#include <stdio.h>
#include <stdint.h>
int main()
{
int8_t num1 = -128; // 8비트(1바이트) 크기의 부호 있는 정수
int16_t num2 = 32767; // 16비트(2바이트) 크기의 부호 있는 정수
int32_t num3 = 2147483647; // 32비트(4바이트) 크기의 부호 있는 정수
int64_t num4 = 9223372036854775807; // 64비트(8바이트) 크기의 부호 있는 정수
printf("%d %d %d %lld\n", num1, num2, num3, num4);
uint8_t num5 = 255; // 8비트(1바이트) 크기의 부호 없는 정수
uint16_t num6 = 65535; // 16비트(2바이트) 크기의 부호 없는 정수
uint32_t num7 = 4294967295; // 32비트(4바이트) 크기의 부호 없는 정수
uint64_t num8 = 18446744073709551615; // 64비트(8바이트) 크기의 부호 없는 정수
printf("%u %u %u %llu\n", num5, num6, num7, num8);
return 0;
}
출력할 때는 int64_t와 uint64_t만 %lld와 %llu로 출력하고 나머지는 %d와 %u로 출력한다.
stdint의 최소 최댓값은 헤더 파일 안에 정의 되어 있어 limits.h헤더파일을 따로 사용하지 않아도 된다.
- 부호 있는 정수(signed) 최솟값: INT8_MIN, INT16_MIN, INT32_MIN, INT64_MIN
- 부호 있는 정수 최댓값: INT8_MAX, INT16_MAX, INT32_MAX, INT64_MAX
- 부호 없는 정수(unsigned) 최솟값: 0
- 부호 없는 정수 최댓값: UINT8_MAX, UINT16_MAX, UINT32_MAX, UINT64_MAX
7.6 퀴즈

정답은 c이다. int는 4바이트이다.

정답은 d이다. unsigned 자료형의 최솟값은 0이다.

정답은 b이다.

정답은 e이다. 자료형으로 크기를 구하려면 괄호에 넣어야 한다.

정답은 c이다.

정답은 e이다.
7.7 연습문제 : 정수형 변수 선언과 오버플로우

정답은 다음 코드와 같다.
unsigned char
unsigned short
long long
7.8 연습문제 : 자료형 크기 구하기

sizeof(int)는 4이기 때문에 sizeof(num1)과 sizeof(num2)의 합은 10이 되어야 하므로 정답은 다음과 같다.
short
long long
7.9 연습문제 : 최댓값 표현하기

정답은 다음과 같다.
#include <limits.h>
SHRT_MAX
LLONG_MAX
7.10 연습문제 : 크기가 표시된 자료형 사용하기

정답은 다음과 같다.
#include <stdint.h>
uint64_t
7.11 심사문제 : 정수형 변수 선언과 오버플로우

정답은 다음코드와 같다.
unsigned short num1;
unsigned int num2;
char num3;
7.12 심사문제 : 자료형 크기 구하기

sizeof(long long)의 크기는 8바이트 이므로 num1과 num2의 크기가 합쳐서 3이 되야 하므로 정답은 다음 코드와 같다.
char num1;
short num2;
7.13 심사문제 : 최솟값 표현하기

밑줄친 부분에 들어갈 코드는 다음과 같다.
#include <limits.h>
7.14 심사문제 : 크기가 표시된 정수 자료형 사용하기

밑줄친 부분에 들어갈 코드는 다음과 같다.
#include <stdint.h>'Project H4C Study Group' 카테고리의 다른 글
| [Project H4C] C언어 코딩도장(3) (0) | 2021.02.18 |
|---|---|
| [Project H4C] C언어 코딩도장(2) (0) | 2021.02.17 |
| [Project H4C] opentutorials HTML(6) (0) | 2021.02.12 |
| [Project H4C] opentutorials HTML(5) (0) | 2021.02.12 |
| [Project H4C] opentutorials HTML(4) (0) | 2021.02.11 |










