fgets 함수로 문자열을 입력 받고, printf 함수로 두 번 출력하고, ebp-0xc 의 값이 0x4030201 이면 main + 120 으로 이동하고, ebp-0xc의 값이 0xdeadbeef이면 main+120으로 이동시킨다. main+120을 보면 ebp-0xc가 0xdeadbeef 가 아닐 경우 main+ 177 로 보내서 main 함수를 종료하고, 같으면 어셈 코드가 진행되다가 system 함수가 실행되게 된다.
프로그램의 동작을 더 확실하게 알기 위해 아이다 헥스레이로 main 함수를 보면 다음과 같다.
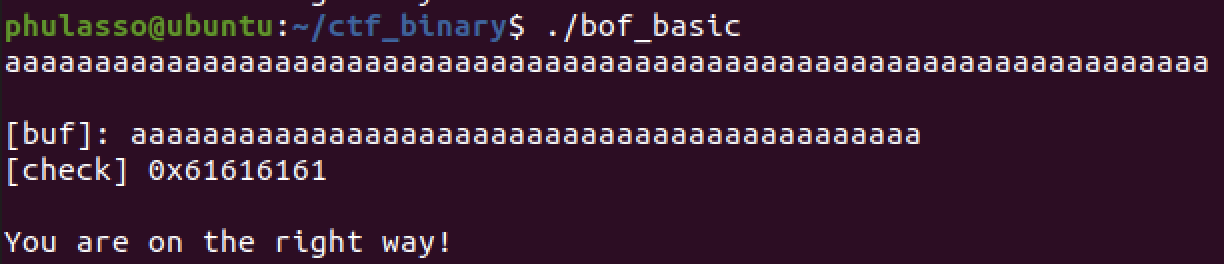
s 라는 문자열을 받는 배열과 , v5 변수가 선언되어 있고, v5는 0x4030201로 할당되어 있고, s에는 입력값이 할당된다. s의 크기는 40이기 때문에 s 변수에서 버퍼 오버플로우를 발생시켜서 v5의 값을 바꾸면 될 것 같다.
일단 프로그램을 실행시키고 40이상의 문자을 입력하면 v5의 값이 변경되어 첫번째 조건문을 만족시킨다.
실행할 때 check 부분에 0xDEADBEEF가 들어가야 할 것 같다.
배열을 40칸 채운 후 리틀 엔디언 방식으로 0xdeadbeef를 넣어주면 시스템 함수가 실행되어 쉘을 딸 수 있다.
struct 키워드 뒤에 구조체 이름을 지정하고 중괄호 안에 변수를 선언한다. 구조체 안에 들어있는 변수를 멤버라고 부른다. 구조체를 정의할 때는 }(닫는 중괄호) 뒤에는 반드시 ; (세미클론)을 붙여줘야 한다. 구조체는 보통 main 함수 바깥에 정의한다. 함수 안에 구조체를 정의하면 해당 함수 안에서만 구조체를 사용할 수 있다.
정의한 구조체를 사용하려면 구조체 변수를 선언해야 하며 구조체 이름 앞에 struct 키워드를 붙여줘야 한다.
구조체 멤버에 접근할 때는 .(점)을 사용한다. p1.age = 30; 과 같이 구조체 멤버에 접근한 뒤 값을 할당하고 값을 가져온다. 문자열 멤버는 할당연산자로 저장할 수 없으므로 strcpy함수를 사용하면 된다.
다음과 같이 중괄호와 세미클론 사이에 변수를 지정하면 구조체를 정의하는 동시에 변수를 선언할 수 있다.
구조체를 정의하면서 닫는 중괄호와 세미클론 사이에 변수를 지정하면 구조체를 정의하는 동시에 변수가 선언된다. 이와 같이 선언된 변수 p1은 main함수 바깥에 선언되어 있으며 전역변수이다.
구조체 변수를 선언하는 동시에 값을 초기화 하려면 중괄호 안에 .(점)과 멤버 이름을 적고 값을 할당한다. 또한 멤버 이름과 할당 연산자 없이 값만 콤마로 구분하여 나열해도 되는데, 이러한 경우 처음부터 순서대로 값을 채워야 하며 중간에 있는 멤버만 값을 할당하거나 생략할 수 는 없다.
struct 구조체이름 변수이름 = { .멤버이름1 = 값1, .멤버이름2 = 값2 };
struct 구조체이름 변수이름 = {값1, 값2};
48.2 typedef로 struct 키워드 없이 구조체 선언하기
typedef로 구조체를 정의하며 별칭(alias)을 지정할 수 있다.
구조체 이름과 구조체 별칭은 겹쳐도 되지만 구분하기 위해 구조체 이름은 앞에 _을 붙이겠다.
strtok함수는 지정된 문자를 기준으로 문자열을 자른 다. 기준 문자는 큰 따옴표로 묶어야 한다. 위의 경우 공백 문자를 넣어 공백을 기준으로 잘랐다. 잘린 문자열을 한 번에 얻을 수 없어서 while 반복문으로 문자열을 계속 자르다가 문자열이 나오지 않으면 반복문을 끝내는 방식을 사용한다.
while 반복문 안의 strtok 함수는 자를 문자열 부분에 NULL을 넣어 주었다. NULL은 직전 strtok 함수에서 처리했던 문자열에서 잘린 문자열 만큼 다음 문자료 이동한 뒤 다음 문자열을 자른다. ptr = strtok(ptr," "); 처럼 잘린 문자열의 포인터를 다시 넣으면 다음 문자로 이동하지 못하고 처음에 나오는 문자열만 자르게 된다. strtok 함수를 사용할 때는 처음에만 자를 문자열을 넣어주고 그 다음부터는 NULL을 넣어줘야 한다.
처음 호출되는 strtok는 공백문자를 찾아서 NULL로 채운 뒤 문자열의 첫 부분인 The를 자른다.
반복문 안의 strtok에 NULL을 넣어주면 앞에서 잘린 문자열 만큼 다음 문자로 이동한 뒤 NULL로 채운뒤 Little를 자른다. 이런 식으로 반복하여 문자열 맨 끝에 있는 NULL문자를 만나면 반복문을 종료한다.
strtok 함수는 문자열을 새로 생성해서 반환하는 것이 아니라 자르는 부분으로 널문자로 채운 뒤 잘린 문자열의 포인터를 반환하는 것이다. 원본 문자열의 내용을 바꾸므로 사용에 주의해야 한다.
45.2 문자열 포인터 자르기
문자열 포인터에 문자열 리터럴이 들어 있어서 읽기 전용인 상태이면 strtok 함수는 사용할 수 없다.
문자열 포인터를 자를때는 동적 메모리를 할당하고, 문자열을 복사하여 이 문제를 해결할 수 있다.
처음에는 s1을 넣어 문자열을 실수로 변환하고, 끝 포인터는 &end처럼 메모리 주소를 넣어 strtof함수가 실행된 후 끝 포인터가 이전 숫자의 끝 부분부터 시작하게 했다. 두 번째 부터는 end를 넣어 이전 숫자의 끝 부분버터 변환한다. double 형 실수로 변환하는 strtod 함수도 있다.
문자열 길이의 절반만큼 반복하며 왼쪽 문자와 오른쪽 문자들을 검색한다. 반복문 안에서 왼쪽문자와 오른쪽 문자를 비교하며 문자가 다르면 isPalindrome 에 false를 넣고 반복문을 끝낸다. 문자열의 마지막 문자는 word[length-1] 이므로 인덱스를 i 만큼 빼주면 오른쪽에서 왼쪽으로 진행할 수 있다.
47.2 N-gram 만들기
N-gram은 문자열에서 N개의 연속된 요소를 추출하는 방법이다. Hello의 경우 2-gram으로 추출하면 다음과 같다.
문자열의 처음부터 끝까지 한 글자씩 이동하며 2 글자씩 추출한다.
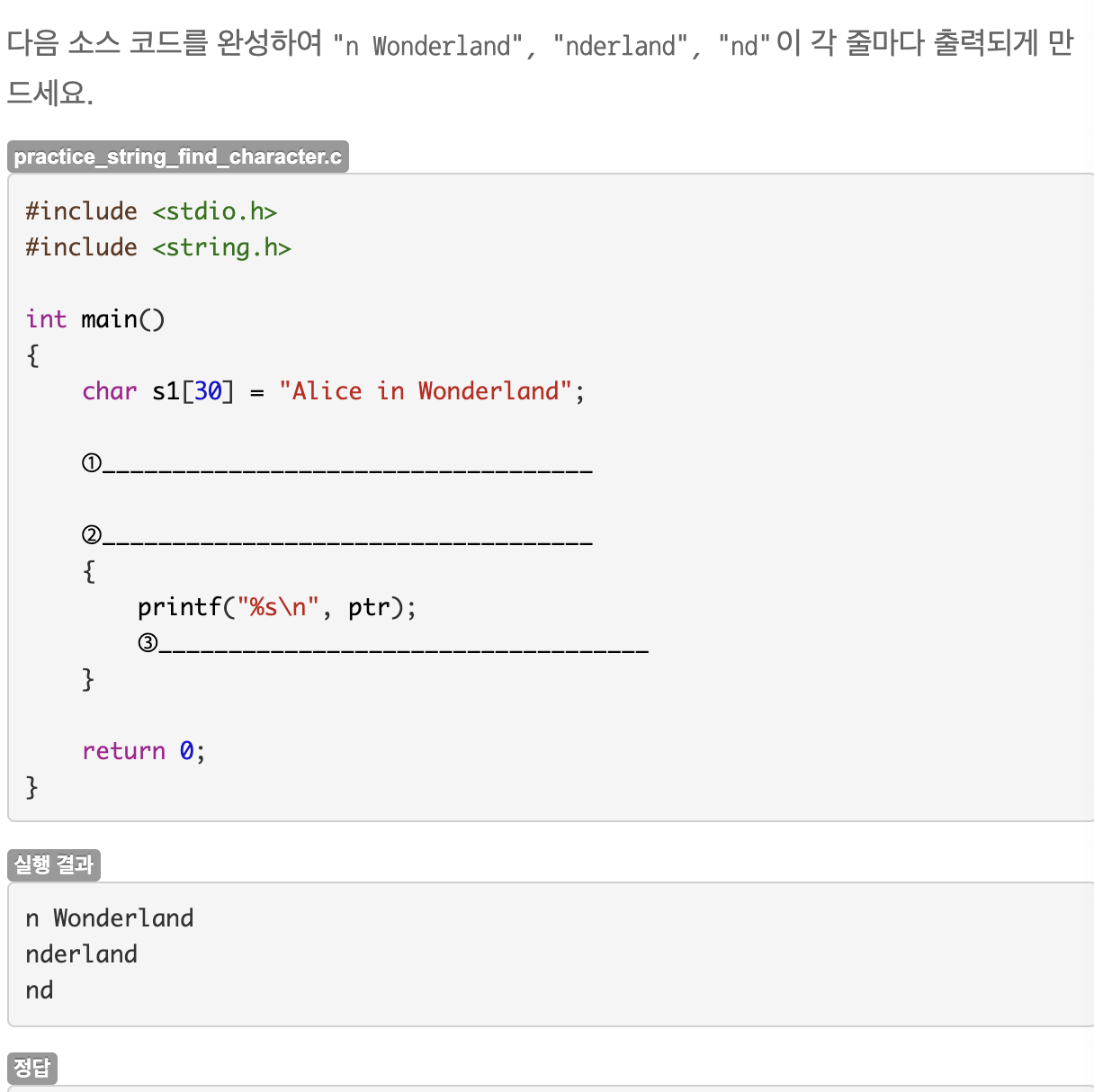
#include <stdio.h>
#include <string.h>
int main()
{
char text[30] = "Hello";
int length;
length = strlen(text);
for(int i = 0; i < length - 1; i++)
{
printf("%c%c\n", text[i], text[i+1]);
}
return 0;
}
2-gram이므로 문자열의 끝에서 한 글자 앞까지만 반복하며 현재 문자와 그 다음문자 두 글자씩 출력한다.
만약 3-gram이라면 조건식은 i < length -2가 될 것이고, 문자열 끝에서 두 글자 앞까지 반복하면 된다.
단어 단위 N-gram도 있다. 다음은 공백을 기준으로 구분하여 단어단위 2-gram을 출력하는 코드이다.
strlen에 문자열 포인터나 문자 배열을 넣으면 문자열의 길이가 반환된다 Hello는 5글자 이기 때문에 5가 출력되었으며 NULL 부분은 포함하지 않는다. 배열의 경우 배열의 크기는 관계없이 문자열의 길이만 구한다. 위 코드의 경우도 배열의 크기는 10이지만 출력값은 문자열의 길이인 5가 나왔다.
41.2 문자열 비교하기
strcmp 함수를 사용하면 두 문자열이 같은 지 비교할 수 있다. string.h 헤더 파일에 선언되어 있다.
aaa는 아스키 코드로 97 97 97 이고, aab 는 97 97 98 이기 때문에 aab 가 더 크다. 또한 aac는 97 97 99 이므로 aac가 aab 보다 크다. 앞의 것이 크면 1, 뒤의 것이 크면 -1을 반환한다. 이것은 윈도우 기준이고, 리눅스나 OS X에서는 코드값의 차이를 반환한다. 따라서 입력받는 두 문자열의 크기를 비교할 땐 윈도우에서는 switch문을 사용하면 되고, 리눅스나 OS X 에서는 if 문을 사용해야 한다.
최종 결과가 나올 문자열 포인터에 char 20개 크기만큼 동적 메모리를 할당하고, 메모리가 할당된 문자열 포인터는 문자열을 직접 할당할 수 없으므로 strcpy 함수를 이용하여 "Hello"를 복사하고, s2 뒤에 s1을 붙인다. 문자열 사용이 끝났으면 free로 동적 메모리를 해제한다.
문자열 포인터 s2 뒤에 문자열을 붙여야 하므로 메모리가 부족하지 않도록 넉넉히 할당하고, strcpy함수로 s2에 "Hello"를 복사한다. 이후 s2 뒤에 strcat 함수로 문자열 배열 s1을 붙이면 된다. 문자열 사용이 끝나면 free로 메모리를 해제해줘야 한다.
42.5 퀴즈
정답은 NULL문자까지 6이다.
정답은 NULL문자까지 11바이트 이다.
정답은 c 이다.
42.6 연습문제 : 문자열 포인터를 배열에 복사하기
문자열을 복사하는 것이므로 strcpy 함수를 사용하여 정답은 strcpy(s2, s1); 이다.
42.7 연습문제 : 문자열 포인터를 동적 메모리에 복사하기
정답은 다음 코드와 같다.
1. malloc(sizeof(char) * 20);
2. strcpy(s2, s1);
42.8 연습문제 : 문자 배열을 붙이기
정답은 strcat(s2, s1); 이다.
42.9 연습문제 : 문자열 리터럴과 동적 메모리 붙이기
정답은 다음 코드와 같다.
1. strcpy(s2, "Alice in");
2. strcat(s2, s1);
42.10 심사문제 : 문자 배열 복사하기
정답은 다음 코드와 같다.
scanf("%s", s1);
strcpy(s2, s1);
s1에는 값을 입력받고, s2에는 s1의 값을 복사해서 가져왔다.
42.11 심사문제 : 두 문자열 붙이기
scanf("%s", s1);
strcat(s1, "th");
문자열을 입력받아 strcat 함수로 문자열 끝에 th를 붙였다.
Unit 43. 문자열 만들기
43.1 서식을 지정하여 배열 형태로 문자열 만들기
sprintf 함수를 사용하면 서식을 지정하여 문자열을 만들 수 있다. sprintf(배열, 서식, 값);의 형태로 사용하며 서식에 값이 들어간 것을 배열에 저장할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
#define _CRT_SECURE_NO_WARNINGS // sprintf 보안 경고로 인한 컴파일 에러 방지
sprintf 함수에 문자열을 저장할 배열과 문자열을 만들 서식, 문자열을 만들 값(문자열)을 순서대로 넣어 %s부분이 "word!"로 바뀌게 된다. 위 코드에서 s1과 같이 문자열을 저장할 빈 배열을 버퍼(buffer)라고 부른다. 서식지정자로 C언어의 다양한 자료형들을 문자열로 만들 수 있다.
strstr 함수에 검색할 문자열을 넣으면 해당 문자열로 시작하는 문자열의 위치(포인터)를 반환한다. 검색한 문자만 나오지 않고, 검색한 문자를 포함하여 뒤에 오는 모든 문자열이 나온다. strstr 함수도 대소문자를 구분하며 다음과 같이 반복문을 사용하여 문자열을 계속 검색할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include<stdio.h>
#include<string.h>
int main()
{
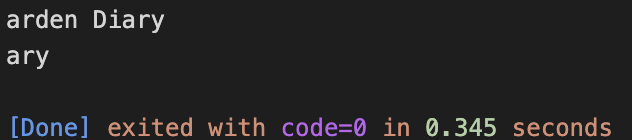
char s1[100] ="A Garden Diary A Garden Diary A Garden Diary";
문자는 글자가 하나만 있는 상태이고, 문자열은 글자 여러 개가 계속 이어진 상태를 의미한다. 문자는 1바이트 크기라 char에 저장할 수있지만, 문자열은 1바이트가 넘어서므로 char에 저장할 수 없다. 따라서 문자열은 변수에 직접 저장하지 않고 포인터를 이용하여 저장한다. 포인터는 메모리 주소를 저장하기 때문에 메모리 주소를 보고 문자열이 저장된 위치로 이동한다. 문자열 리터럴이 있는 메모리 주소는 읽기 전용이기 때문에 다른 문자열을 덮어 쓸 수 없다. 문자열 리터럴이 저장되는 위치는 컴파일러가 결정한다.
문자열은 ""(큰따옴표)로 묶어야 하며 문자열을 출력할 때는 서식지정자 %s를 사용해야 한다.
C에서 문자열은 마지막 끝에 항상 널문자가 붙는다. NULL은 0으로 표현할 수 있으며 문자열의 끝을 나타낸다.
문자열에 배열을 저장하는 방식은 배열 요소 하나하나에 문자가 저장된다. 배열이기 때문에 인덱스는 0부터 시작하고, 문자열의 맨 뒤에 NULL이 들어간다. 남는 공간에도 모두 NULL이 들어간다.
배열로 문자열을 사용할 때는 무조건 배열을 선언한 즉시 문자열로 초기화해야 한다. 이미 선언한 배열에는 문자열을 할당할 수 없으며 정 할당하고 싶으면 요소에 문자 하나 하나를 넣으면 된다.
배열을 선언할 때는 배열의 크기를 할당할 문자열보다 크게 지정해야 한다. 문자열 문자 개수보다 배열의 크기가 작다면 컴파일은 되지만 문자열이 제대로 출력되지 않는다. 문자열은 마지막에 NULL이 꼭 들어가야 하므로 문자 개수에 하나 더한 크기가 문자열을 저장할 수 있는 배열의 최소 크기 이다.
scanf 함수에 서식지정자로 %s를 넣어서 문자열을 입력받을 수 있다. 매개변수는 입력값을 저장할 배열을 넣는데, 배열 앞에는 일반 변수와 달리 &를 붙이지 않는다. 위 코드에서는 크기가 10인 배열을 선언했으므로 문자열 맨 뒤에 붙는 널문자 까지 포함하여 총 10개의 문자를 저장할 수 있다. 따라서 실제 저장할 수 있는 문자는 9개이다.
scanf에서 %s로 문자열을 저장할 때 입력된 문자열에 공백이 있다면 배열에는 공백 직전까지만 저장된다. 공백을 포함하여 저장하고 싶다면 서식지정자로 %[^\n]s를 사용하면 된다.
40.2 입력 값을 문자열 포인터에 저장하기
문자열 포인터를 선언한 뒤 scanf 함수로 입력 값을 문자열 포인터에 저장하고 실행하면 에러가 발생한다. 이미 할당된 문자열 포인터에 저장된 메모리 주소는 읽기만 할 수 있고, 쓰기가 막혀있기 때문이다.
입력값을 문자열 포인터에 저장하려면 문자열이 들어갈 공간을 따로 만들어야 한다. malloc 함수로 메모리를 할당한 뒤 문자열을 저장하면 된다.
char 10개 크기 만큼 동적 메모리를 할당하여 입력값을 문자열 포인터 s1에 저장할 수 있다. 입력 받을 때 s1은 포인터이므로 &를 붙이지 않는다. 문자열 사용이 끝나면 free 함수로 메모리를 해제해야 한다. 문자열 중간에 공백이 있다면 문자열 포인터에는 공백 직전까지만 저장된다.
문자열 두 개를 저장하기 위한 공간을 선언하고, scanf 함수에서 서식지정자로 %s를 두 개 넣어준다. 문자열이 저장될 배열을 두 개 넣어주면 공백으로 구분된 문자열을 입력받을 수 있다. 문자열을 더 입력받고 싶으면 %s와 입력받을 배열(또는 문자열 포인터)의 개수를 늘려주면 된다.
소스 코드가 없을 경우 IDA의 헥스레이 기능을 활용하면 다음과 같이 바이너리를 디컴파일 하여 원본 코드와 흡사한 소스를 보여준다. f5 단축키를 이용하여 사용할 수 있다. (헥스레이 기능이 매우 편리할 것 같아서 조만간 IDA나 헥스레이 기능이 있는 무료 툴인 기드라를 설치해야 겠다.)
IDA에서 8번째 라인을 보면 strcpy((char *) &v4, argv[1]); 코드에서 버퍼오버플로우 취약점이 있다. argv[1]을 v4 변수에 복사할 때 버퍼 크기를 검증하는 코드가 없기 때문이다. 변수 v4와 v5는 지역변수 이기 때문에 스택에 할당되고, length가 검증되지 않은 v4에 argv[1]의 값이 복사될 때 v4는 할당받은 공간 그 이상을 사용하게 되고, v5가 v4보다 높은 주소에 할당되어 있다면 v5에 원하는 값을 삽입할 수 있다. strcpy는 버퍼오버플로우 취약점이 발생할 가능성이 있기 때문에 strcpy_s로 대체하여 사용하는것을 권고하고 있다.
main 함수의 어셈 코드는 다음과 같다.
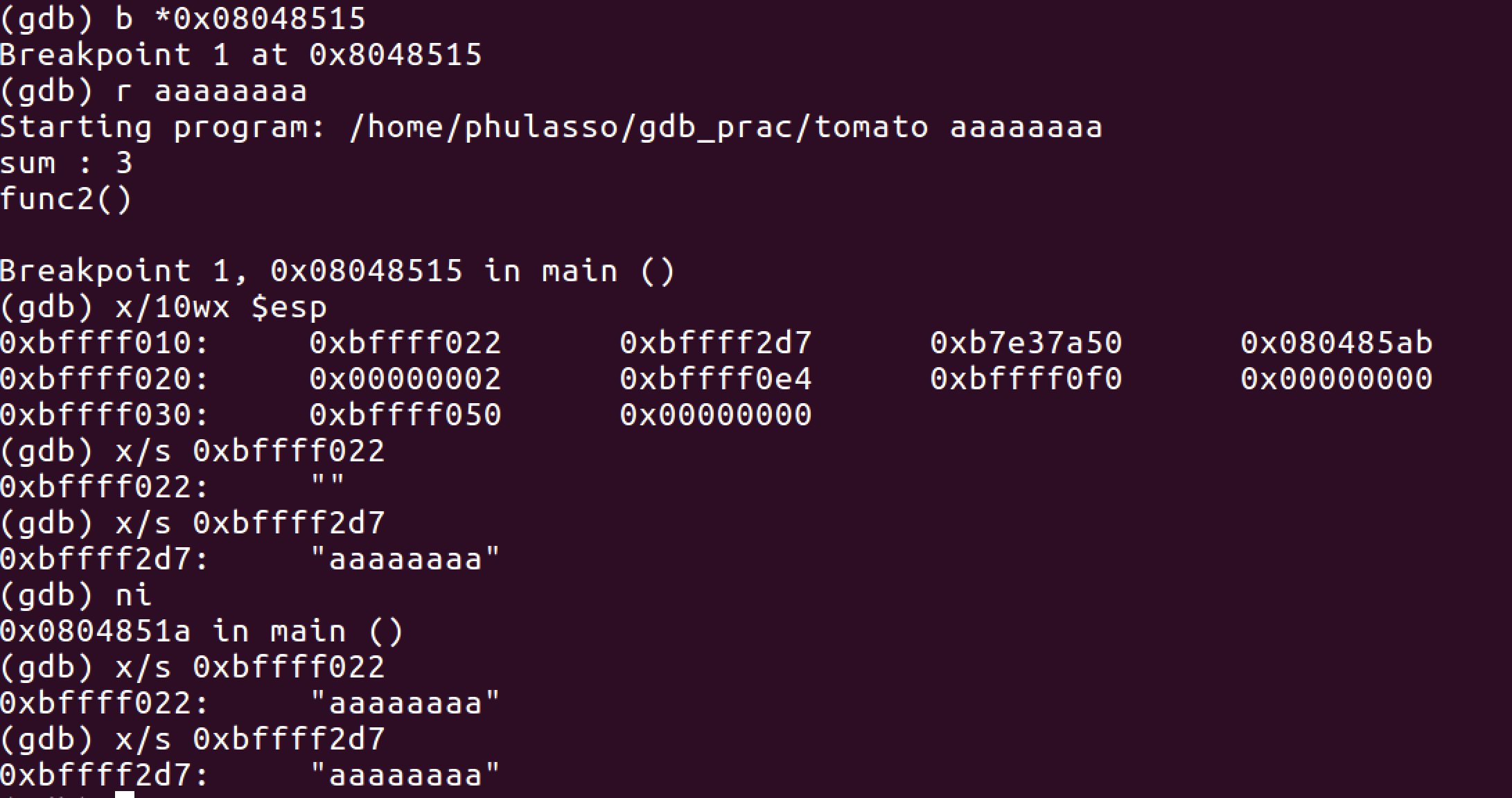
strcpy 함수의 주소는 0x08048515이므로 이 위치에 breakpoint를 걸고 strcpy가 실행되기 전후의 스택을 확인할 것이다.
0xbffff022는 esp가 가리키는 값 즉, v4이고, 0xbffff2d7은 esp+0x4가 가리키는 값 즉 argv[1]이다. strcpy 호출 전에는 argv[1]에만 값이 들어 있다가 strcpy로 v4에도 값이 들어간 것을 확인할 수 있다.
다음은 main의 어셈코드 일부이다.
cmp는 비교하는 명령으로 첫번째 값에서 두번째 값을 뺄 때 마이너스가 되면 CF=1, 0이면 ZF=1 플래그가 설정된다. 플래그는 CPU의 플래그 레지스터에 저장되는 처리 데이터 이다. 플래그의 설정에 따라 분기문 조건이 다르다. 아래 jne의 경우 jump not equal로 비교 결과가 다르면 main+108 주소로 점프한다. 이 주소로 점프할 경우 system 함수를 실행하지 않는다. 따라서 ebp-0xc의 값이 0x1 이여야 system 함수를 실행하는 것이다.
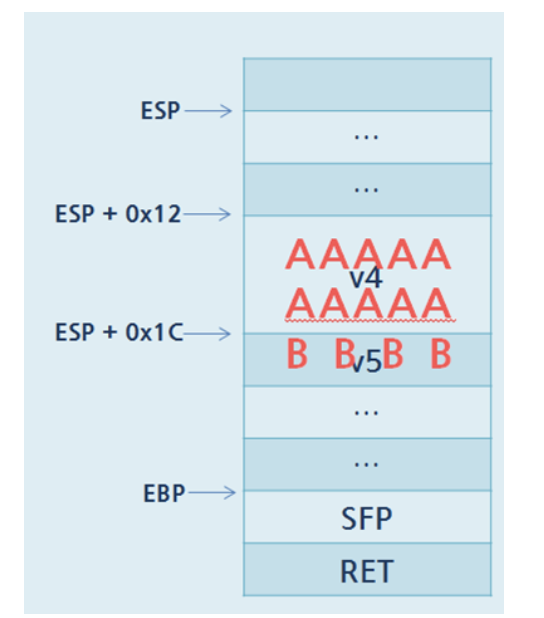
현재 스택의 구조는 다음과 같다.
v4의 값이 흘러 넘치면 v5에도 영향을 미칠수 있다.
v4의 범위가 벗어나서 이후 메모리에 42(B)가 들어간 것을 확인할 수 있다.
v4의 값을 흘러넘치게 해서 v5가 0x00000001이 되면 셸을 띄울 수 있을것이다. B로 채워진 부분들이 0x00000001이 되면 조건문은 일치시켜서 셸을 띄울 수 있을 것 같다.
다음과 같이 넣으면 gdb로 확인했을 때 다음과 같다.
메모리에 들어가는 값을 보면 0x00000001이 아닌 다른 값이 들어가는 것을 확인할 수 있다. 문자열 00000001이 들어가는 것이다. hex값을 메모리에 넣으려면 다음과 같이 python 이나 perl 같은 스크립트 언어를 사용하여 넣어야 한다.
python -c 옵션을 사용하면 command 라인에서 출력할 수 있고, 커맨드의 출력값은 `(백틱)을 이용해서 넘길 수 있다. tomato 파일의 인자로 백틱으로 감싼 파이썬 명령을 넣으면 v5 변수에 0x00000001을 덮어쓸 수 있다.
파이썬 명령어가 tomato 파일의 인자로 들어가서 v4 변수를 덮어쓰고 v5 도 0x00000001로 채워서 셸이 따지는 것을 확인할 수 있다.
이 소스코드에서 sum함수는 코드 내부에서 a + b의 결과값을 출력해주는 함수를 새로 만든 것이고, strcpy() 함수는 문자열을 다른 배열이나 포인터(메모리)로 복사하는 함수이다. system함수는 인수로 실행시킬 프로세스의 이름을 받아 그 프로세스를 실행하는 것이다.
이 소스코드는 다음 명령으로 컴파일 한다.
gcc -fno-stack-protector -o tomato tomato.c
-fno-stack-protector 옵션을 사용하는 이유는 gcc는 스택을 보호하기 위해 'canary' 라는 것을 삽입하여 함수 내에서 사용하는 스택 프레임과 return address 사이에 canary를 넣는다. 만약 Buffer Overflow가 발생하여 canary를 덮으면 이를 감지하고 프로그램을 강제 종료 한다. 이 과정을 SSP(Stack Smashing Protection)이라고 한다. 해당 옵션을 사용라게 되면 오버플로우가 발생해도 프로그램이 강제 종료 되지 않도록 보호기법을 해제한 것이다.
반대로 모든 프로시저에 이 보호기법을 적용하려면 -fstack-protector-all 옵션을 사용하면 된다.
gdb는 오픈소스로 공개되어 있는 무료 디버거로 코드에서 어떤 라인을 실행할 때 어떤 값이 어떤 메모리 주소에 올라가는지 과정을 보여주는 것이다.
다음과 같은 명령어로 gdb로 프로그램을 실행할 수 있다.
gdb ./tomato
gdb로 tomato를 실행하면 다음과 같은 화면이 나온다.
보기 편하도록 어셈코드를 인텔 형식으로 설정하려면 다음 명령어를 사용한다.
set disassembly-flavor intel
at&t 형식으로 보려면 intel 자리에 att를 넣으면 된다.
disas main으로 main함수의 어셈블리 코드를 확인하면 다음과 같다.
b는 breakpoint를 거는 명령으로 b *[메모리주소]의 형태로 사용한다. 메모리 주소에는 메모리 주소, 함수의 이름, 이를 기준으로 한 offset <+0> 으로 걸어도 된다.
모두 같은 주소에 breakpoint가 걸림을 확인할 수 있다.
info b 명령으로 breakpoint 정보를 확인할 수 있다.
breakpoint가 중복되니 삭제한다.
삭제할때는 d (breakpoint 번호) 의 형태로 삭제한다.
프로그램을 실행할 때는 run 명령을 사용하는데 뒤에 매개변수를 넣을 수 있다.
위와 같은 실행은 터미널에서 ./tomato aaaaaaaaaa로 실행한 것과 동일하다.
main 함수의 시작 위치에 breakpoint를 걸었기 때문에 main 함수를 확인해 보면 => 화살표로 main에 멈춰있는 것을 확인할 수 있다.
ni 명령을 통해 인스트럭션을 한줄 한줄 실행할 수 있다.
ni를 몇번 더 해서 원문과 비슷한 위치에 eip가 멈추도록 했다.
현재 멈춘곳 이전의 인스트럭션을 보면 esp 값을 ebp 값에 저장하고 있다. esp, ebp는 스택에 관련된 레지스터 이다.
그 메모리에 어떤 값이 담겨있는지 확인하기 전에 메모리 출력 방식에 대해 정리하겠다.
몇바이트 만큼, 몇 진법으로 출력할 지 옵션을 주어 출력할 수 있다.
해당 메모리 주소의 값을 각각 1바이트, 2바이트, 4바이트 만큼 출력한 것이다. x/ 뒤에 b는 1바이트, h는 2바이트, w는 4바이트를 의미한다.
위는 해당 메모리 주소 값을 각각 16진수 10진수로 출력한 것이다.
다음과 같이 두 바이트 옵션과 진법 옵션을 같이 사용할 수 있다.
위를 보면 4바이트 출력한 것과 1바이트씩 4개를 출력한 것이 순서가 반대이다. Intel CPU는 바이트를 배열할 때 거꾸로 써서 예를 들어 0x12345678을 저장한다고 하면 0x78563412처럼 거꾸로 저장하는 것이며 이를 Little Endian 이라 지칭한다.
gdb는 디버깅시 보기 편하게 하기 위해 Big Endian 형식으로 0x12345678와 같이 출력하기 때문에 1바이트씩 출력할 때와 4바이트로 출력할 때 달리보인다.
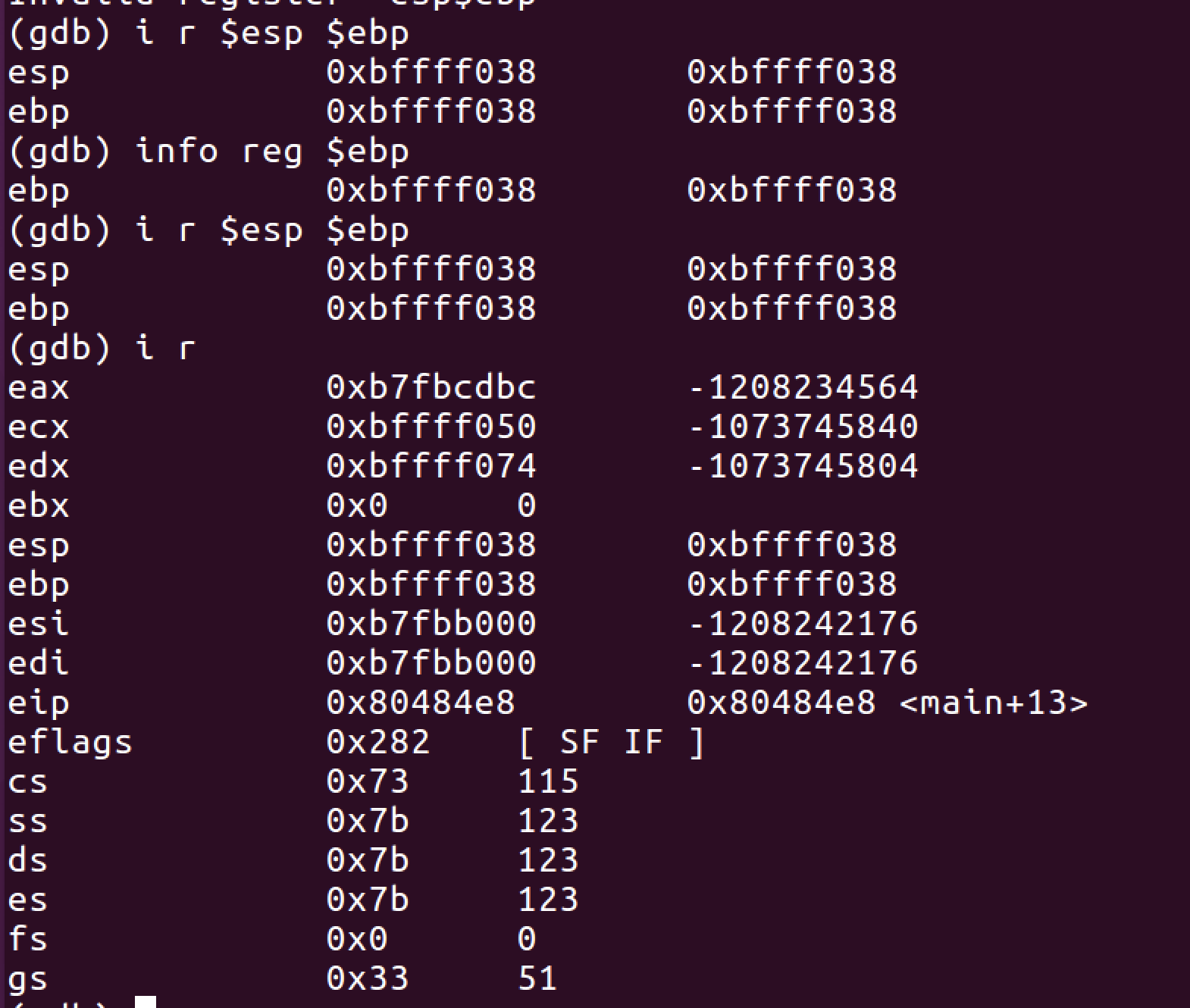
특정 레지스터를 기준으로 메모리 값을 보고 싶으면 다음과 같이 $register_name로 출력할 수 있다.
info reg 또는 i r 명령을 사용하면 레지스터 정보를 출력할 수 있다.
스택과 관련있는 레지스터의 종류는 다음과 같다.
EBP : 스택의 가장 밑바닥 주소를 가진 레지스터
ESP : 스택의 가장 상단 주소를 가진 레지스터
EIP : 현재 실행중인 명령의 주소를 가진 레지스터
현재 EIP의 상황은 화살표가 가리키고 있고, 그 전에 실행된 push ebp 와 mov ebp, esp라는 두 줄의 어셈 코드가 의미하는 것은 스택(프레임)이 생성된다는 것이다. 저 두 줄의 의미는 함수가 실행이 될때 그 이전의 ebp(sfp)를 스택에 push 하고, 현재 esp를 ebp에 저장하라(새로운 ebp 생성)는 뜻이다. push는 스택 포인터를 하나씩 증가시키는 어셈 코드이다.
이제 sum 함수에 breakpoint를 걸고 실행시킨 후 스택의 상황을 볼것이다. breakpoint까지 한번에 실행하려면 c명령을 사용하면 된다.
sum의 함수 위치에 정확히 멈춰있는 것을 확인할 수 있다.
sum 함수가 call 되기 전의 상황은 다음과 같다.
sum 함수의 주소는 0x80484b4 이기 때문에 이 위치에 breakpoint를 걸고 함수 안으로 들어가면 스택 esp(0x00000001)위에 다음 인스트럭션의 주소가 쌓일 것이다.
이 함수의 어셈 코드를 확인해 보면 다음과 같다.
이 함수도 마찬가지로 push ebp, mov ebp,esp로 시작하고 있다. push ebp를 실행하면 그 이전 스택프레임(main)의 ebp 가 sum의 스택프레임에 push 되서 main의 ebp 0xbffff038이 esp에 들어갈 것이다.
그리고 mov ebp, esp를 실행하면 현재 esp를 sum stack frame의 바닥 즉, sum의 ebp가 되서 sum의 ebp에는 main의 ebp가 있게 될 것이다.
상단 첫번째 줄의 상태는 다음과 같다.
새 스택프레임의 ebp를 기준으로 return address는 ebp-4, 매개인자는 ebp-8, ebp-12에 들어가게 된다.
다음은 sum의 어셈 코드이다.
sum함수 안에서 func2 함수를 호출하고 있다. func 함수 주소에 breakpoint를 걸고 실행한 모습은 다음과 같다.
스택의 모습은 func2 stack frame, sum stack frame, main stack frame 가 차례로 있을 것이다.
구간별로 나눠보면 다음과 같다.
현재 eip의 상황은 다음과 같다.
leave 실행 전의 스택 상황은 다음과 같다.
leave 를 실행한 후 스택의 상황은 다음과 같다.
위에서 빨간색으로 표시해둔 func2의 stack frame이 정리되며 ebp가 sum의 ebp로 바뀌고 esp도 sum의 esp로 바뀐다. 그리고 ret를 만나면 0x080484d8로 리턴해서 나머지 sum의 인스트럭션을 실행하고, sum의 스택프레임을 정리하고 나머지 main의 인스트럭션도 실행한 후 프로그램은 종료된다.
4GB는 위의 계산 과정을 거치면 2^32 byte 사이즈의 메모리라는 것을 알 수 있다.
1 byte는 주소 공간 한 개의 크기 이기 때문에 4GB는 2^32개의 주소를 가질 수 있다.
1bit는 0 과 1 의 값만 가지기 때문에 32bit는 2^32만큼의 숫자를 표현할 수 있다.
메모리는 주소로 접근하는데 32비트 운영체제는 수 표현을 2^32까지 밖에 못하기 때문에 8GB 이상의 램을 가지고 있어도 접근할 수 없다.
따라서 4GB 메모리 주소의 범위는 0x00000000 ~ 0xFFFFFFFF 까지 인 것이다.
시스템 운영에 필요한 메모리, 운영체제는 커널 영역에 올라가 있다. 사용자가 운영체제가 올라가 있는 커널영역에 마음대로 접근할 수 있다면 시스템이 안정적으로 운용될 수 없기 때문에 사용자가 함부로 커널 영역에 접근할 수 없도록 메모리를 유저영역과 커널영역으로 나누어 사용하는 것이다. 나누는 크기는 운영체제마다 다르고, 설정에 따라 영역의 크기를 조정할 수 있다.
유저 메모리 영역의 구조는 다음과 같다.
먼저 메모리에 코드가 올라온다. C소스를 컴파일하면 어셈블리 코드로 바뀌는데 이 코드가 코드 영역에 올라가는 것이다. 주소는 32bit 시스템은 주로 0804~ 로 시작되는 영역에 올라간다.
데이터 영역은 전역변수가 로드되는 영역으로 항상 동일한 메모리에 위치하게 된다. 만약 사용자가 입력하는 값이 전역변수로 정의되어 있으면 고정된 메모리 주소에 원하는 값을 쓸 수 있게 되어 익스플로잇에 활용될 가능성이 높아질 수 있다.
힙 영역은 동적메모리를 할당하여 사용하는 공간이다. 대표적인 메모리 할당 함수로는 malloc이 있다. malloc로 필요한 공간을 할당하면 힙 영역을 쓰고, 쓰다가 필요 없으면 free로 해제하면 된다. 이때 힙 영역에 어떤 값을 엄청 많이 할당하고 free해준후 이 공간을 재사용하면 익스플로잇에 활용될 수 있다. 이러한 기법을 UAF라 한다.
스택영역은 메모리의 가장 바닥부터 채워진다. 스택은 높은 주소에서 부터 거꾸로 자란다. 그래서 스택 영역의 주소는 보통 0xbfff 이런식이다. 스택에 계속 자라다가 커널 영역을 건드리면 안되기 때문이다. 스택 영역은 함수 인자나 지역변수들이 올라온다.
일반 텍스트 파일은 글자로만 이루어진 파일이다. 이러한 텍스트 파일은 cat 명령어로 출력한다.
프로그램 소스 파일은 컴퓨터 언어로 입력한 파일이며 컴파일 이라는 과정을 거쳐 실행 가능하도록 만든 후 사용한다.
텍스트 파일은 다음과 같이 생성할 수 있다.
1. 쉘 프롬프트에서 cat > 파일이름.txt 라고 입력
2. 원하는 내용 작성
3. control + D키 입력
1번 과정에서 > 문자는 리다이렉션 이라고 부르며 cat의 결과를 모니터가 아닌 파일로 보내는 것이다.
리다이렉션을 한 번 사용하면 새로운 파일이 만들어지지만, 기존의 내용을 보존시키면서 글자를 추가하려면 다음과 같이 리다이렉션을 두 번 사용하면 된다.
cat >> 파일이름.txt
소스 파일을 만드는 방법도 텍스트 파일과 동일하지만 언어를 컴퓨터 언어인 C언어로 작성한다는 차이가 있다.
C언어로 소스 작성이 끝났으면 컴파일을 해야 프로그램을 실행할 수 있다.
컴파일은 다음과 같이 진행한다.
gcc -o 프로그램이름 소스파일이름
프로그램을 실행할때는 만들어진 프로그램이 있는 경로에서 실행해야 한다. 내가 만든 프로그램의 이름은 program.exe 이기 때문에 /home/trainer8/program.exe 를 입력하면 프로그램이 실행된다. 또한 현재 디렉토리를 의미하는 . 을 이용하여 ./program.exe처럼 상대경로로 현재 디렉토리에 있다면 바로 실행할 수 있다.
Lesson 9
리눅스는 각 사용자마다 특별한 권한을 부여하여 그 권의 범위를 넘어서지 않는 파일들만 제어할 수 있도록 설정되어 있다. ls -al 명령으로 파일들의 권한에 대한 정보를 출력할 수 있다.
리눅스의 권한에는 4가지 종류의 사용자가 있다.
user(유저) : 아이디로 로그인 한 자기 자신을 의미한다.
group(그룹) : 모든 유저는 하나 이상의 그룹에 속하게 된다. 그 그룹을 따로 변경하지 않는 한 자신의 유저네임과 같은 이름의 그룹에 속하게 된다.
other(아더) : 유저와 그룹을 제외한 모든 다른 사람을 의미한다.
root(루트) : 절대적인 권한을 가진 사용자이다. 어떤 권한에도 구애받지 않고 파일들을 제어할 수 있다.
id 라는 명령을 사용하면 다음과 같이 출력된다.
uid는 User ID의 약자이다. id라는 명령을 통해 현재 로그인한 계정의 uid는 2009라는 것을 알 수 있다.
gid는 group ID의 약자이다. 다른 사람을 자신의 gid를 가진 그룹에 속하게 할 수 있고, 특별한일이 없는 한 gid는 항상 uid와 같다.
groups는 현재 자신이 어떤 그룹에 속해있는지 말해준다. 임의의 변경이 없으면 기본으로 uid와 같은 그룹에 속하게 된다.
위는 ls -al 로 test1 이라는 파일을 확인한 것이다. rwxrwxrwx를 보면 rwx rwx rwx 로 3문자씩 끊었을 때 각각 유저, 그룹, 아더의 권한을 의미한다. 영문자 r, w, x는 순서대로 읽기(r), 쓰기(w), 실행(x) 권한을 의미한다. 위 예시에서 trainer9 자리가 유저, trainer10 자리가 그룹을 의미한다. 이 둘을 제외한 모든 아이디는 아더이다.
따라서 위의 test1 파일은 trainer9 라는 uid를 가진사람과 tranier10이라는 gid를 가진 사용자, 이 둘을 제외한 다른 모든 사람들에게 읽기, 쓰기, 실행 권한이있다. 즉 아이디가 있는 모든 사용자는 이 파일을 마음대로 접근하고 변경할 수 있다.
위 test2 파일의 경우 guest라는 uid를 가진 사용자는 읽기, 쓰기, 실행 권한이 있고, trainer1 이라는 gid를 가진 사용자는 읽기 실행 권한이 있고, 이 둘을 제외한 다른 모든 사용자는 실행 권한만 갖는다.
읽기 권한은 cat 명령으로 파일을 볼 수 있는 권한이고, 쓰기 권한은 그 파일의 수정 권한이다. 실행권한은 윈도우에서 exe 파일처럼 실행할 수 있는 파일로 리눅스에서는 확장자로는 실행파일인지 확인할 수 없고, 권한에서 x라는 문자가 있는지 확인하고 판단해야 한다.
루트 권한만 접근할 수 있는 shadow 파일의 권한은 다음과 같다.
Lesson 10
해킹방식에는 Local 해킹과 Remote 해킹 두가지 종류의 방식이 있다.
Remote 해킹은 자신의 해킹하고자 하는 서버에 아이디가 없을 때 아이디를 얻고자 시도하는 것이다.
Local 해킹은 해킹 하고자 하는 서버에 일반 계정이 있을 때 관리자 권한을 얻고자 시도하는 것이다.
SetUID는 일시적으로 자신의 ID를 변경하는 것을 말한다. passwd 명령어를 사용하여 패스워드를 바꾸는 경우 shadow파일은 루트만 수정권한이 있는데 일반 사용자도 패스워드를 변경할 수 있다. 이러한 경우 passwd에 SetUID가 걸려 있어 passwd 파일을 실행하는 동안 루트로 일시적인 아이디 변경이 되는 것이다.
SetUID는 필요한 만큼만 관리자 권한을 제공하고 그 일이 끝나면 다시 가져가는 것이 일반적이지만 SetUID가 걸린 파일들을 통해서 관리자 권한을 완전히 가져오게 될수도 있다.
버퍼 오버플로우의 경우 루트 권한으로 SetUID가 걸려 있는 파일에 프로그램의 에러를 발생시키고 에러가 나는 순간 /bin/bash 파일을 실행하게 조작하여 프로그램이 실행되는 동안 루트 아이디로 변경되고, 그 상태에서 /bin/bash를 실행해 루트 권한의 쉘을 획득하는 공격이다.
다음과 같이 x권한이 올 자리에 s가 있으면 SetUID가 설정된 것이다. s는 x(실행권한)도 포함한다.
이 파일은 모든 사용자에게 실행권한이 있지만 root에 SetUID가 걸려있기 때문에 어느 사용자가 저 파일을 실행해도 루트의 권한을 갖는다.
find / -perm -4000 의 명령을 사용하면 서버 전체에서 SetUID가 걸린 모든 파일을 찾을 수 있다. 위 명령을 해석하면 / 에서부터 적어도 SetUID가 걸린 모든 파일을 찾으라는 명령이다. 4는 SetUID를 의미하며 000은 rwx모두를 의미한다.
find 명령의 옵션은 다음과 같다.
-perm : 권한과 일치하는 파일을 찾음
-name : 이름과 일치하는 파일을 찾음
-user : 유저와 일치하는 파일을 찾음
-group : 그룹과 일치하는 파일을 찾음
위 옵션들을 조합하여 사용할 수 도 있다. find / -user root -perm 4000은 루트 권한으로 SetUID가 걸린 파일을 찾는 것이다.
FTZ의 이후 레벨별 문제들은 다음 레벨로 SetUID가 걸린 파일을 찾아서 그 파일을 이용하여 그 레벨의 쉘을 얻으면 된다. 쉘을 얻고 my-pass를 입력하면 해당 계정의 패스워드를 확인할 수 있다.
tmp : 임시로 파일을 저장하는 디렉토리, 권한 관계없이 누구나 파일을 생성할 수 있다.
usr : 다양한 응용 프로그램들이 설치되어 있는 디렉토리
var : 시스템 운영 중에 생성되는 각종 임시 파일들, 외부 접속에 대한 로그 파일들이 저장되는 위치
리눅스의 중요한 역할을 하는 파일들은 다음과 같다.
/etc/passwd : 사용자들에 대한 간단한 정보
/etc/shadow : 사용자들의 패스워드가 암호화하여 저장됨
/etc/services : 서버가 어떤 서비스를 하는 중인지 보여줌
/etc/issue.net : 처음 접속할 때 나오는 화면( FTZ의 경우 해커스쿨의 F.T.Z에 오신걸 환영합니다! 라는 문구)
/etc/motd : 로그인 후에 나오는 메시지
~/public_html : 각 사용자들의 홈페이지 파일
다음은 FTZ의 퀴즈와 답이다.
Lesson 5
whoami : 접속한 자기 계정이 누구인지 확인하는 명령어
id: 접속한 계정에 대한 더 많은 정보
cat : 파일을 읽는 명령어
다음은 cat명령어로 /etc/passwd 파일을 읽은 것의 일부이다.
각 줄의 가장 왼쪽의 단어가 사용자들의 아이디 이다.
커널은 리눅스의 심장부 역할을 하는 파일로, 커널 버전에 따라 리눅스의 성능 차이가 발생할 수 있다. 같은 버전의 리눅스라도 커널 버전이 높다면 속도도 빨라지고, 안정성도 높아진다.
uname -a 명령으로 커널 버전을 확인할 수 있다.
위 FTZ의 경우 커널 버전은 2.4.20이고, 2.2.18이전 버전의 모든 커널들은 취약점을 가지고 있다고 한다.
root권한은 리눅스나 유닉스에서 모든 파일을 관리하는 절대적인 관리자 권한이다. 리눅스는 여러명의 사용자가 동시에 작업을 하기에 자신에게 권한이 부여된 파일만 제어할 수 있지만, 루트 권한을 가진 사용자는 어떠한 권한에도 구속되지 않고, 서버를 조정할 수 있다.
서버에 설치된 OS는 cat 명령어로 /etc/*release라고 입력하면 확인할 수 있다.
Red Hat Linux 9 버전임을 확인할 수 있다.
패키지의 정보는 rpm -qa명령으로 확인할 수 있다.
위는 명령 실행 결과의 일부로 많은 패키지들이 깔려 있음을 확인할 수 있다.
cat명령어로 /proc/cpuinfo를 확인하면 서버의 cpu정보를 확인할 수 있다.
Lesson 6
/etc/passwd(이하 패스워드 파일)은 한 서버를 사용하는 사용자들의 모든 정보를 기록해 놓은 파일이다. 사용자의 아이디, 어떤 함호를 이용하여 로그인을하는지, 속한 그룹, 이름 등의 정보가 들어있다.
다음은 패스워드 파일의 root 계정이 있는 줄을 가져온 것이다.
: 은 필드를 구분해주는 문자이다.
첫 번째 필드는 로그인 할 때 사용되는 아이디이다. 두번째 필드는 원래 패스워드가 적혀있는 부분인데 리눅스 버전 6.0 이후 크래커들이 악용을 막기 위해 두번째 필드의 패스워드를 없애버리고 따로 모아 저장하는 /etc/shadow 라는 파일을 사용한다. /etc/shadow파일은 일반 사용자 계정들은 접근할 수 없다.
세 번째 필드는 컴퓨터가 사용자를 인식하기 위한 숫자이다. 0은 root를 의미한다. 네번째 필드는 사용자가 속해있는 그룹을 말해준다.
다섯번째 필드는 사용자 이름을 말해주는 부분이다. 위의 경우 관리자를 의미하는 Admin이 사용자 이름이다. 여섯 번째 필드는 해당 사용자가 로그인 성공했을 때 위치하게 되는 홈 디렉토리 이다. 7번째 필드는 사용자가 처음으로 로그인 했을 때 실행되게 할 프로그램이다. 위 처럼 로그인 했을 때 쉘이 실행되도록 하는 것이 일반적이다.
Lesson 7
리눅스는 서버의 용도로 사용되기 때문에 데이터들의 손실을 막기 위해 백업을 필수적으로 해야 하며 백업할 때는 압축 명령어 들이 사용된다.
tar은 여러개의 파일을 하나로 합치는 명령어이다. 옵션은 다음과 같다.
c - Create : 새로운 파일을 만듬
x : eXtract : 압축 해제
v : View : 압축이 되거나 풀리는 과정을 출력
f : File : 파일로서 백업을 하겠다는 옵션
따라서 파일을 합칠때는 cvf, 해제할 때는 xvf 를 사용한다.
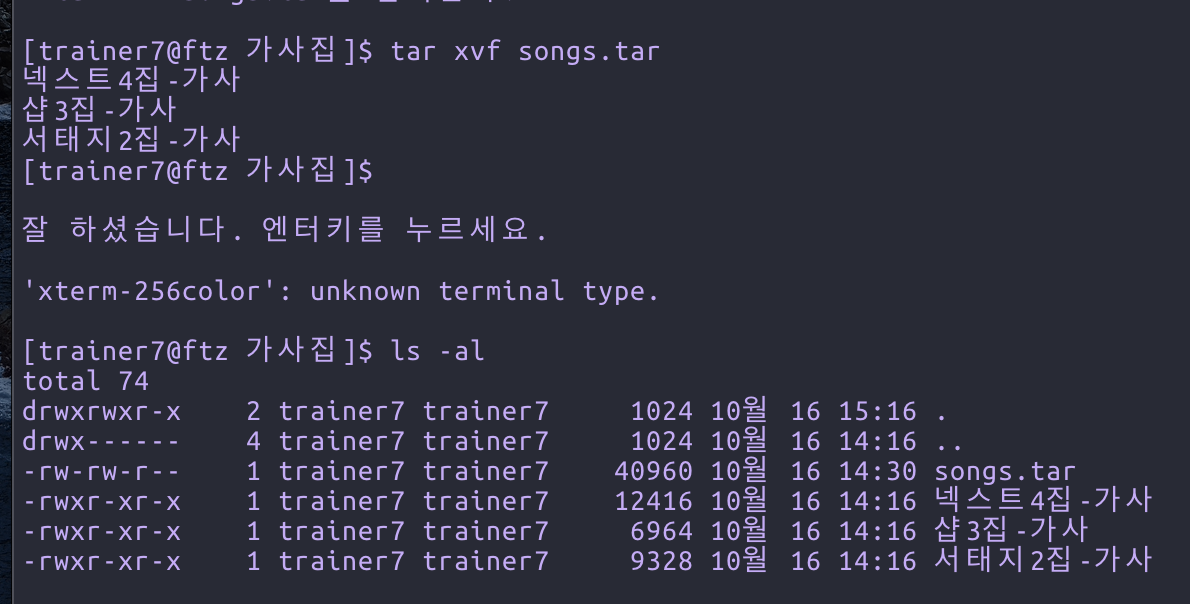
위 명령은 현재 디렉토리의 모든 파일(*)을 songs.tar 이라는 이름으로 합친 것이다.
실제로 다음과 같은 파일이 생성됨을 확인할 수 있다.
위 만들어진 파일의 용량 부분을 보면 3개의 파일을 뭉쳤는데 용량은 오히려 더 증가하였다. tar은 압축하지 않고, 파일을 합쳐버리기만 할 때 사용된다. 또한 gzip은 한 번에 한개의 파일만 압축할 수 있기 때문에 여러개의 파일을 압축하려면 tar로 파일을 합친 뒤 압축해야 한다.
gzip을 사용하여 tar로 합친 파일을 압축하면 다음과 같이 용량이 줄은것을 확인할 수 있다.