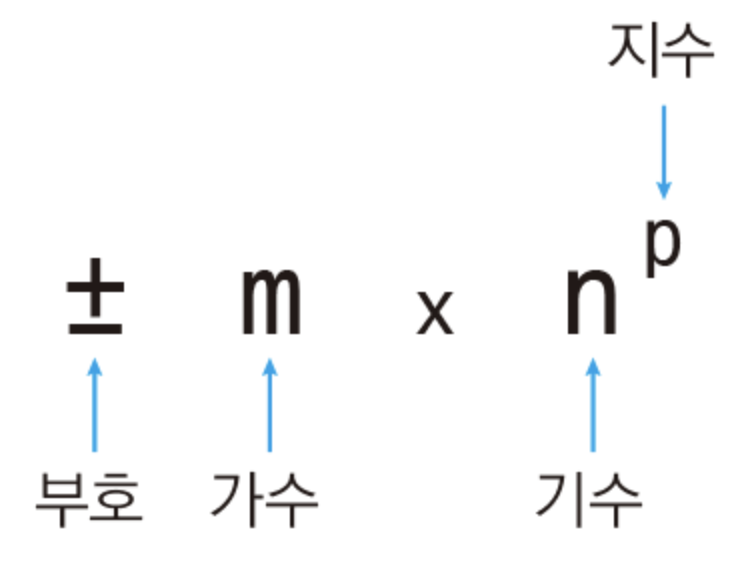
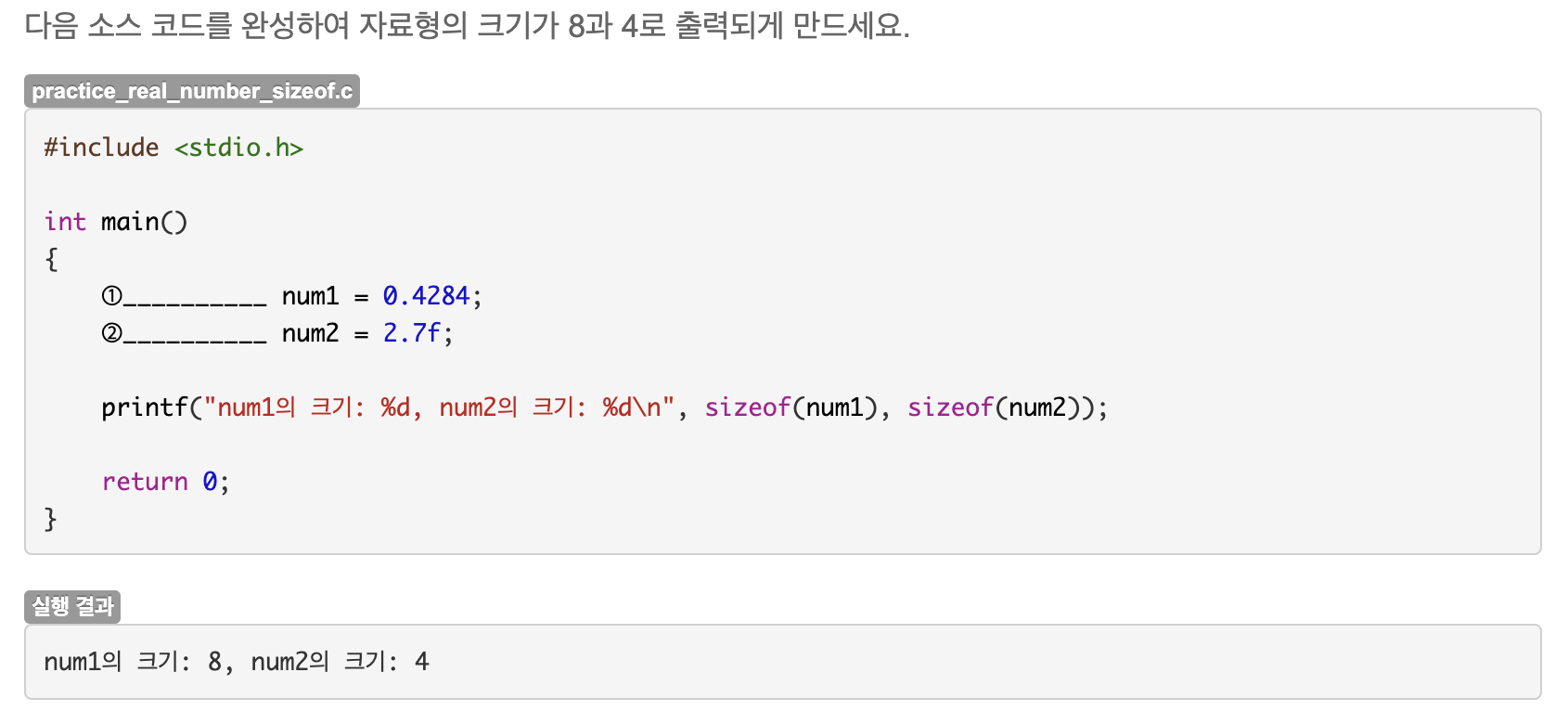
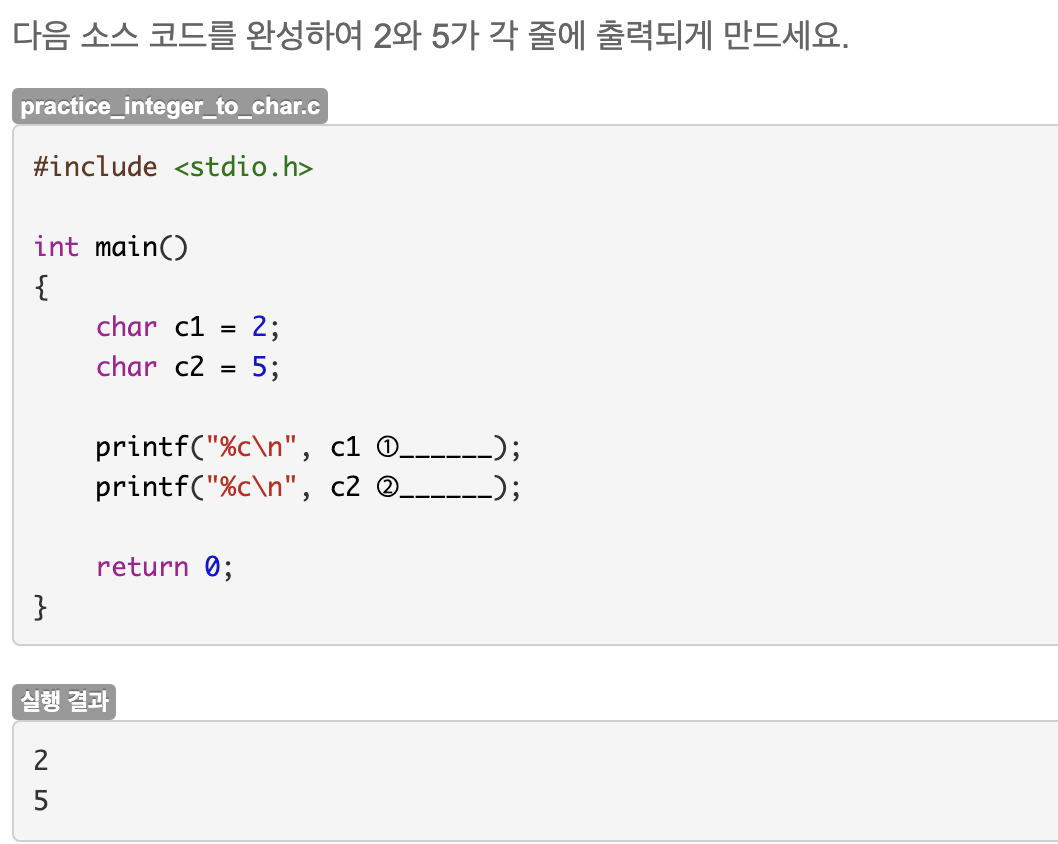
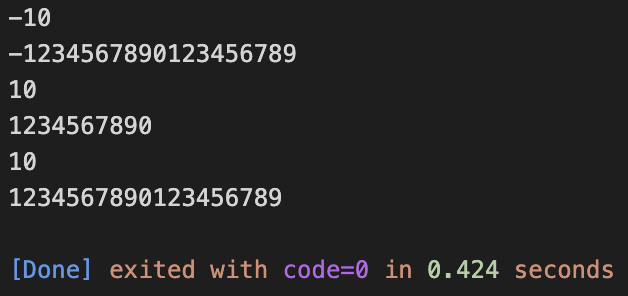
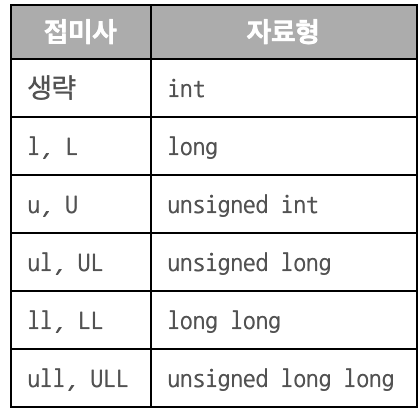
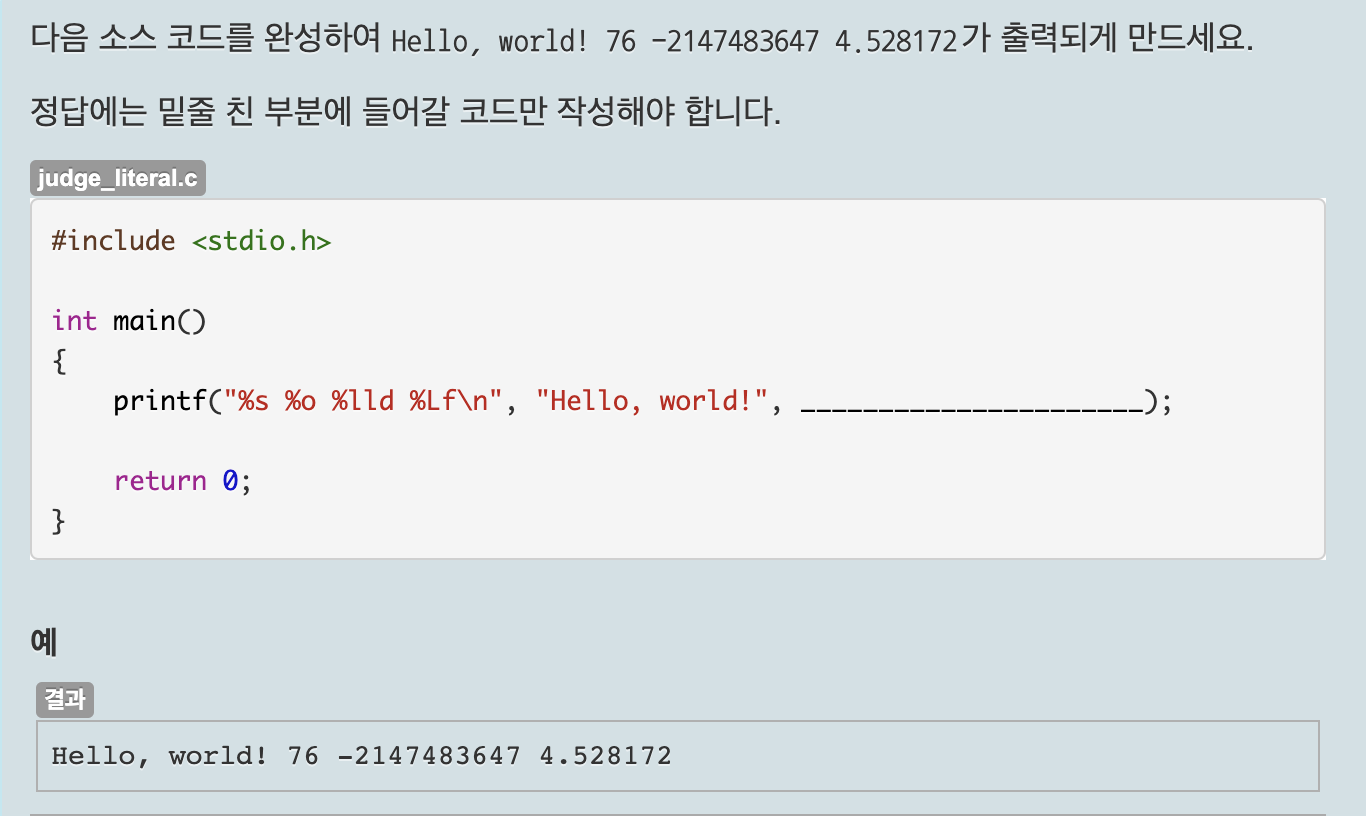
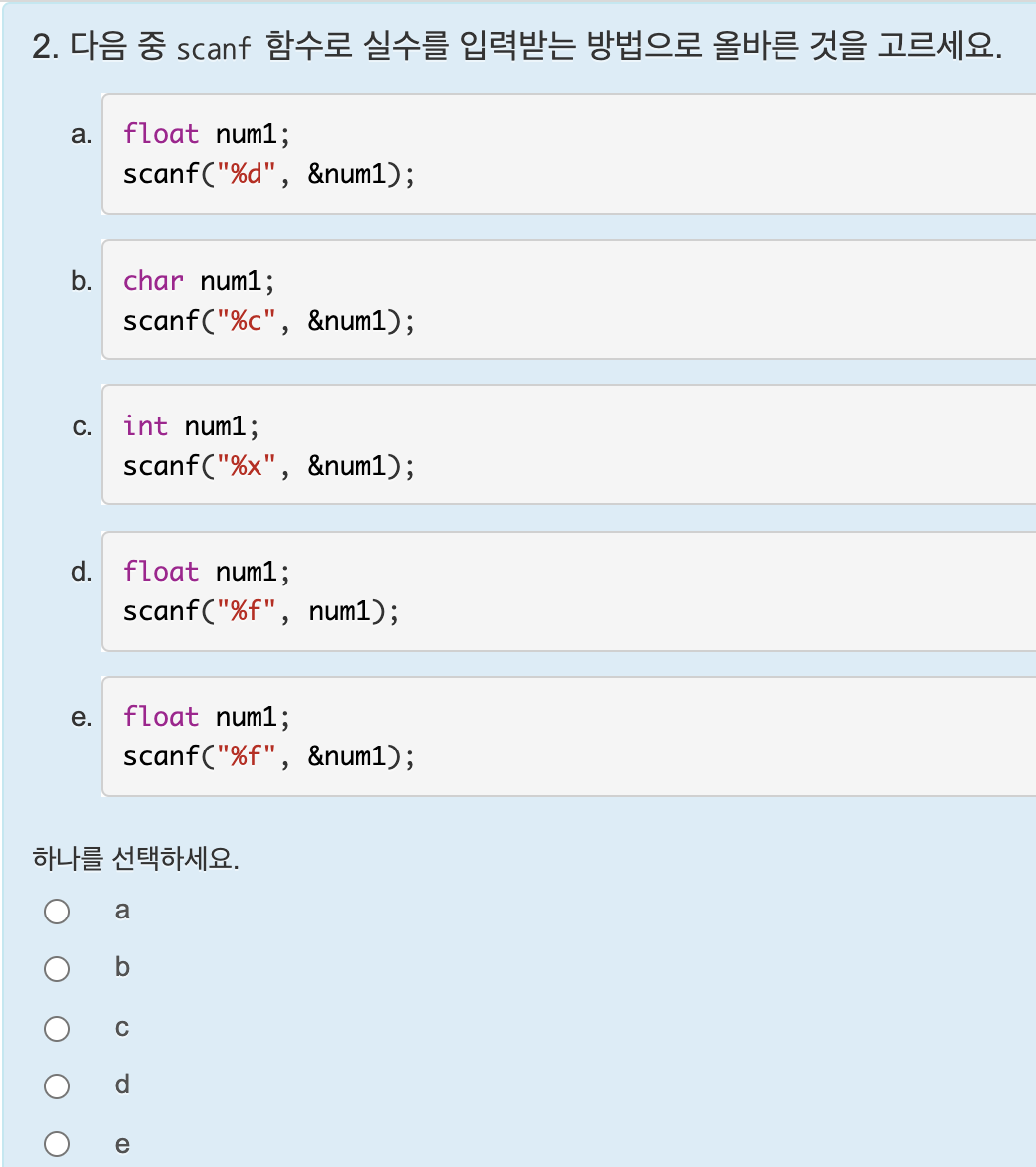
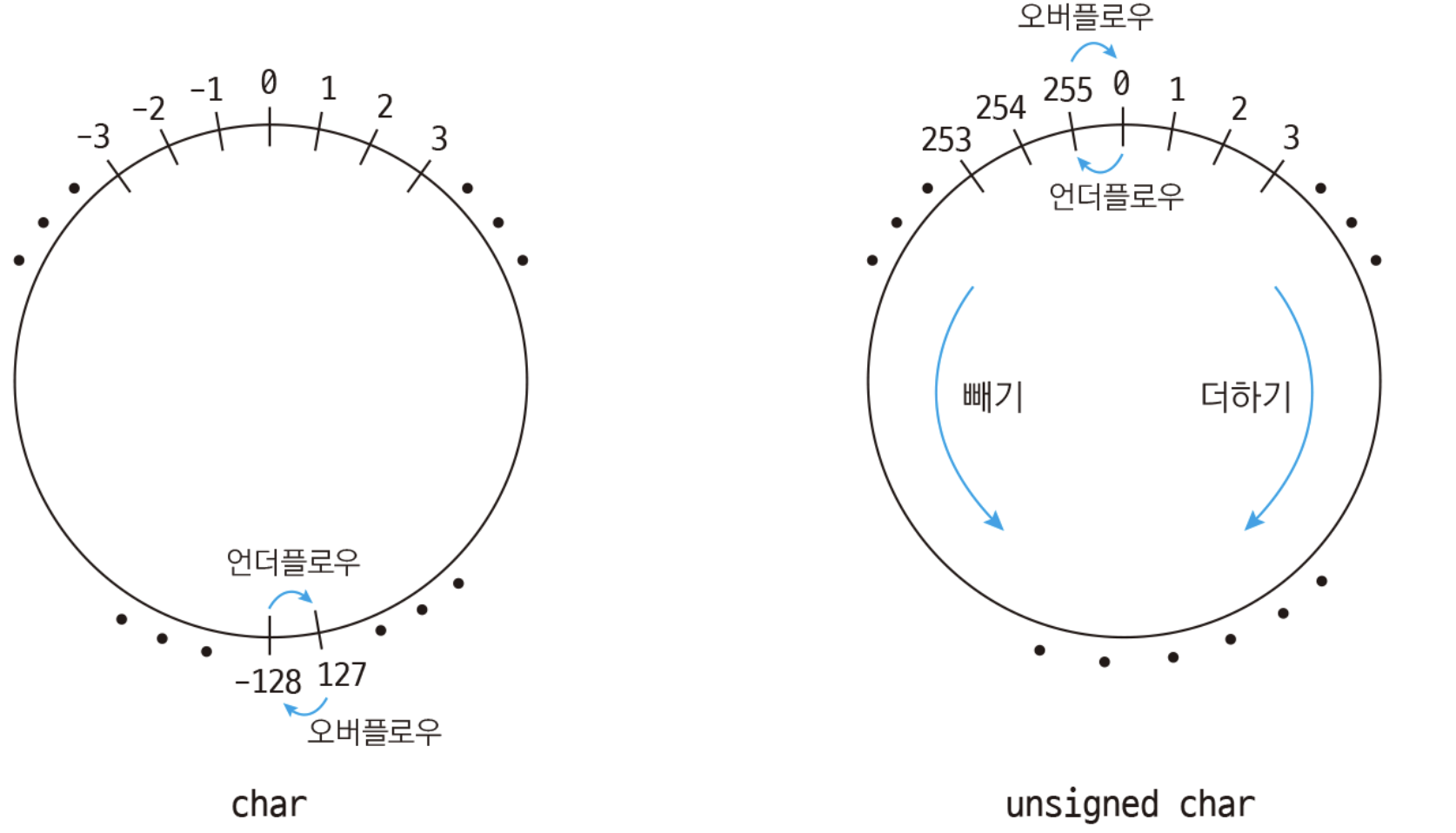
Unit 15. 나머지 연산하기
정수끼리 나눗셈을 하는 경우 몫만 반환하기 때문에 나머지를 구하는 연산도 존재한다.
15.1 나머지 연산하기
나머지 연산은 % 연산자를 사용한다. 완전히 나누어지면 나머지는 0이된다.
#include <stdio.h>
int main()
{
printf("%d\n", 1 % 3);
printf("%d\n", 2 % 3);
printf("%d\n", 3 % 3);
printf("%d\n", 4 % 3);
printf("%d\n", 5 % 3);
printf("%d\n", 6 % 3);
return 0;
}
2 % 3 처럼 나눌 수 없더라도 나머지는 구할 수 있다.(몫은 0, 나머지는 2) 6 % 3 처럼 완전히 나누어지면 나머지 연산의 값은 0이 나온다. 그래서 나머지 연산은 특정 수의 배수인지 확인할 때 주로 사용한다. 나머지 연산은 정수에서만 사용할 수 있고 실수에서 사용하면 컴파일 에러가 발생한다. 또한 5 % 0 처럼 0으로 나눈 나머지는 구할 수 없다.
실수끼리 나누었을 때 나머지는 math.h 헤더 파일의 fmod, fmodf, fmodl 함수를 이용하여 구할 수 있다. fmod는 double, fmodf는 float, fmodl은 long double자료형일 때 사용한다.
#include <stdio.h>
#include <math.h>
int main()
{
double num1 = 7.0;
double num2 = 2.0;
printf("%f\n", fmod(num1, num2));
float num3 = 7.0f;
float num4 = 2.0f;
printf("%f\n", fmodf(num3, num4));
long double num5 = 7.0l;
long double num6 = 2.0l;
printf("%Lf\n", fmodl(num5, num6));
return 0;
}
15.2 변수 하나에서 나머지 연산하기
#include <stdio.h>
int main()
{
int num1 = 7;
num1 = num1 % 2;
printf("%d\n", num1);
return 0;
}
위 연산은 num1에서 2로 나눴을 때 나머지를 num1에 다시 저장한 것이다. 나머지 연산도 할당연산자 %=를 제공한다.
#include <stdio.h>
int main()
{
int num1 = 7;
num1 %= 2;
printf("%d\n", num1);
return 0;
}
a % b의 연산을 진행할 때 두 수의 부호가 다르면 앞(a)의 부호를 따른다.
15.3 퀴즈

정답은 c이다.

정답은 b이다.

정답은 d이다.
15.4 연습문제 : 3의 배수인지 확인하기
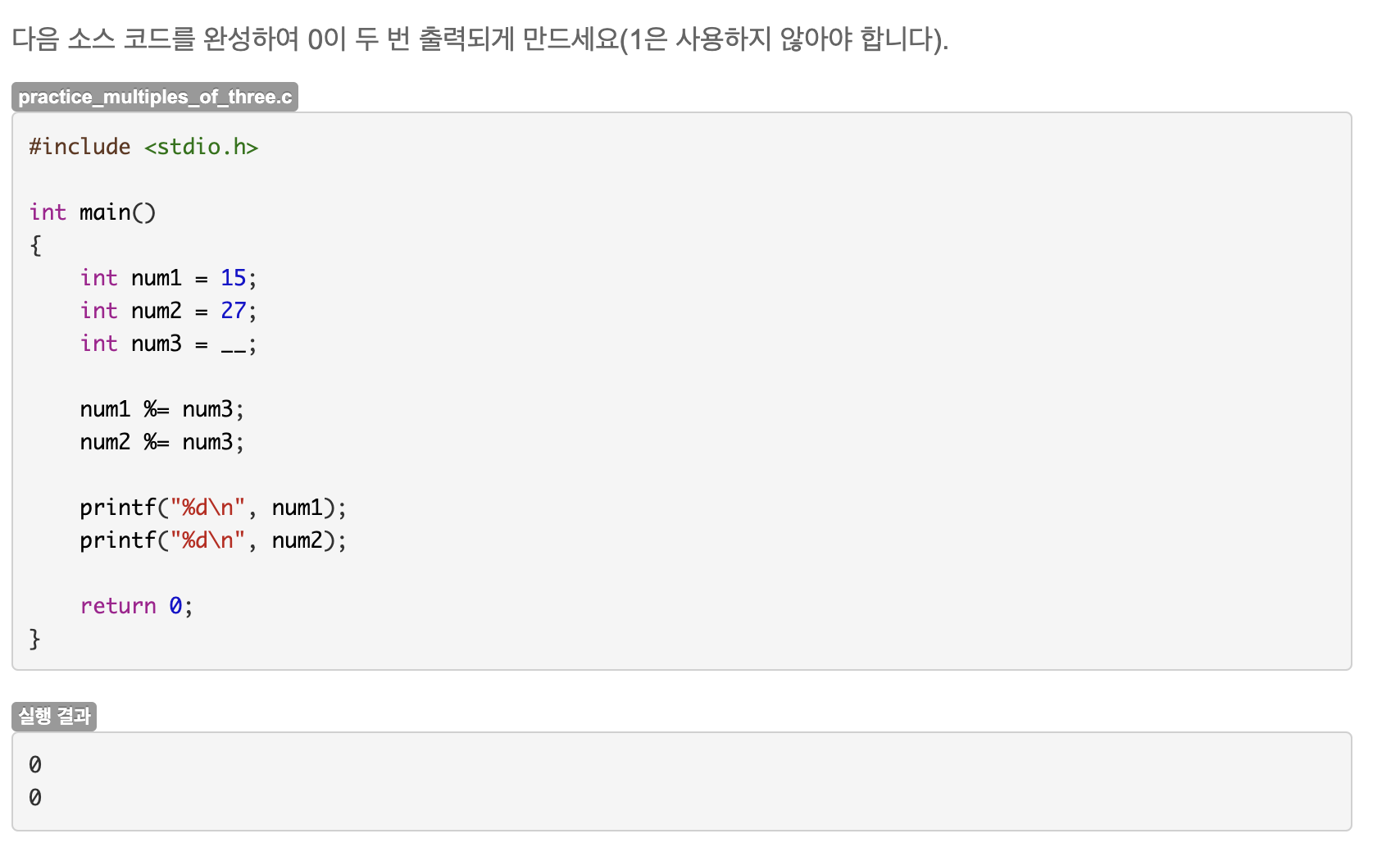
출력 결과가 둘다 0이 나와야 하므로 3과 나눴을 때 나머지 값이여야 한다. 정답은 3이다.
16.5 심사문제 : 정수의 각 자리수를 역순으로 출력하기

정답은 다음 코드와 같다.
#include <stdio.h>
int main()
{
int num;
scanf("%d", &num);
printf("%d ", num % 10);
num /= 10;
printf("%d ", num % 10);
num /= 10;
printf("%d ", num % 10);
num /= 10;
printf("%d ", num % 10);
num /= 10;
printf("%d ", num % 10);
return 0;
}입력 값을 10으로 나눴을 때 나머지를 출력하고 10으로 나눠서 몫만 저장하는 것으로 각 자리를 1의자리부터 출력했다.
Unit 16. 자료형의 확장과 축소 알아보기
16.1 자료형의 확장 알아보기
정수와 실수를 연산하면 다음과 같다.
#include <stdio.h>
int main()
{
int num1 = 11;
float num2 = 4.4f;
printf("%f\n", num1 + num2);
printf("%f\n", num1 - num2);
printf("%f\n", num1 * num2);
printf("%f\n", num1 / num2);
return 0;
}
결과값은 실수로 나온다. 실수가 정수보다 표현 범위가 넓기 때문이다. C에서는 자료형을 섞어서 사용하면 컴파일러에서 암시적 형변환을 하는데, 자료형의 크기가 큰쪽, 표현 범위가 넓은 쪽으로 변환한다. 이를 형확장이라 한다.
다음은 크기가 다른 정수끼리 연산한 것이다.
#include <stdio.h>
int main()
{
long long num1 = 123456789000;
int num2 = 10;
printf("%lld\n", num1 + num2);
printf("%lld\n", num1 - num2);
printf("%lld\n", num1 * num2);
printf("%lld\n", num1 / num2);
return 0;
}
4바이트인 int형과 8바이트인 long long형 중 크기가 더 큰 long long 형으로 변환되었다.
16.2 자료형의 축소 알아보기
다음과 같이 실수에서 정수로 범위가 적은 쪽으로 변환하면 값의 손실이 일어난다.
#include <stdio.h>
int main()
{
float num1 = 11.0f;
float num2 = 5.0f;
int num3 = num1 / num2;
printf("%d\n", num3);
return 0;
}
11.0에서 5.0을 나누면 2.2가 나오지만 정수로 형변환 되면서 0.2가 버려졌다. 이와 같이 자료형의 크기가 작은쪽, 표현범위가 좁은쪽으로 변환되는 것을 형 축소라 한다.
형 축소가 일어나면 컴파일할 때 다음과 같이 값의 손실이 일어날 수 있다고 경고가 나온다.

컴파일 경고가 나오지 않게 하려면 형 변환(type conversion, type casting, 타입 캐스팅)을 해야 한다. 형변환은 자료의 손실을 감안하여 구현하거나, 자료형을 숨기고 싶을 때 등 사용한다.
다음은 크기가 다른 정수끼리 연산을 한 것이다.
#include <stdio.h>
int main()
{
char num1 = 28;
int num2 = 1000000002;
char num3 = num1 + num2;
printf("%d\n", num3);
return 0;
}
char과 int를 연산하면 char자료형의 크기보다 큰 숫자는 저장할 수 없기 때문에 위 코드의 경우 앞의 숫자들은 버려지고 28 + 2만 저장된다. 버려지는 자릿수를 2진수로 표현하면 다음과 같다.

16.3 퀴즈

정답은 d이다.

정답은 c이다.
16.4 연습문제 : 문자 출력하기

정답은 char이다.
16.5 심사문제 : 실수를 정수로 변환하기

정답은 다음 코드와 같다.
int num2 = num1;
printf("%d\n", num2);
Unit 17. if 조건문으로 특정 조건일 때 코드 실행하기
조건문을 사용하면 조건에 따라 다른 코드를 실행할 수 있다.
17.1 if 조건문 사용하기
if 조건문은 다음과 같이 괄호 안에 조건식을 지정하여 사용한다.
if (조건식)
{
코드
}#include <stdio.h>
int main()
{
int num1 = 10;
if (num1 == 10)
{
printf("10입니다.\n");
}
return 0;
}
C에서는 조건문을 if() 형식으로 사용하며 괄호 안에는 조건식이 들어간다. {} 중괄호 안에는 조건식이 만족할 때 실행할 코드가 들어간다.
위 코드의 경우 num1이 10과 같은지 검사하고 있다. ==은 같다를 의미하며 수학의 =(등호)와 같은 의미이다. 위 코드에서 num1은 10으로 조건식을 만족하기 때문에 아래 코드를 실행한다.
파이썬의 if문은 조건식을 괄호로 감싸지 않아도 되고 조건식 끝에 :(클론)을 붙이며, 실행할 코드는 중괄호가 아닌 들여쓰기하여 작성한다는 점에서 문법상의 차이가 있다.
17.2 if 조건문과 세미클론
if 조건문을 사용할 때는 조건식 뒤에 ;(세미클론)을 붙이면 안된다.
if (num1 == 10);
{
printf("10입니다.\n");
}위 코드와 같이 조건식 뒤에 세미클론을 붙이면 조건식 아래 코드는 조건식과 관계 없는 코드가 된다. 따라서 조건이 만족하지 않아도 항상 아래의 printf함수를 실행하게 된다.
if (num1 == 10);
printf("10입니다.\n");실제로는 위와 같은 형태인 것이다. C에서는 코드를 중괄호로 감싸도 에러가 발생하지 않아서 if 조건문을 무시하고 코드가 동작한다.
17.3 if조건문에서 중괄호 생략하기
if 조건문에서 수행할 코드가 한 줄이면 다음과 같이 중괄호를 생략할 수도 있다.
#include <stdio.h>
int main()
{
int num1 = 10;
if (num1 == 10)
printf("10입니다.\n");
return 0;
}
위 코드와 같은 조건식도 뒤에 세미클론을 붙이면 안된다. 코드가 두 줄 이상일 때는 중괄호를 생략할 수 없다. 중괄호를 생략하게 되면 다음과 같이 조건이 일치하지 않아도 두번째 코드는 실행되게 된다.
#include <stdio.h>
int main()
{
int num1 = 5;
if (num1 == 10)
printf("if조건문\n");
printf("10입니다.\n");
return 0;
}
중괄호가 없을 때 if 조건식의 영향을 받는 것은 한 줄 뿐이다.
17.4 if 조건문에서 실수와 문자 비교하기
다음과 같이 정수가 아닌 실수와 문자도 비교할 수 있다.
#include <stdio.h>
int main()
{
float num1 = 0.1f;
char c1 = 'a';
if (num1 == 0.1f) // 실수 비교
printf("0.1입니다.\n");
if (c1 == 'a') // 문자 비교
printf("a입니다.\n");
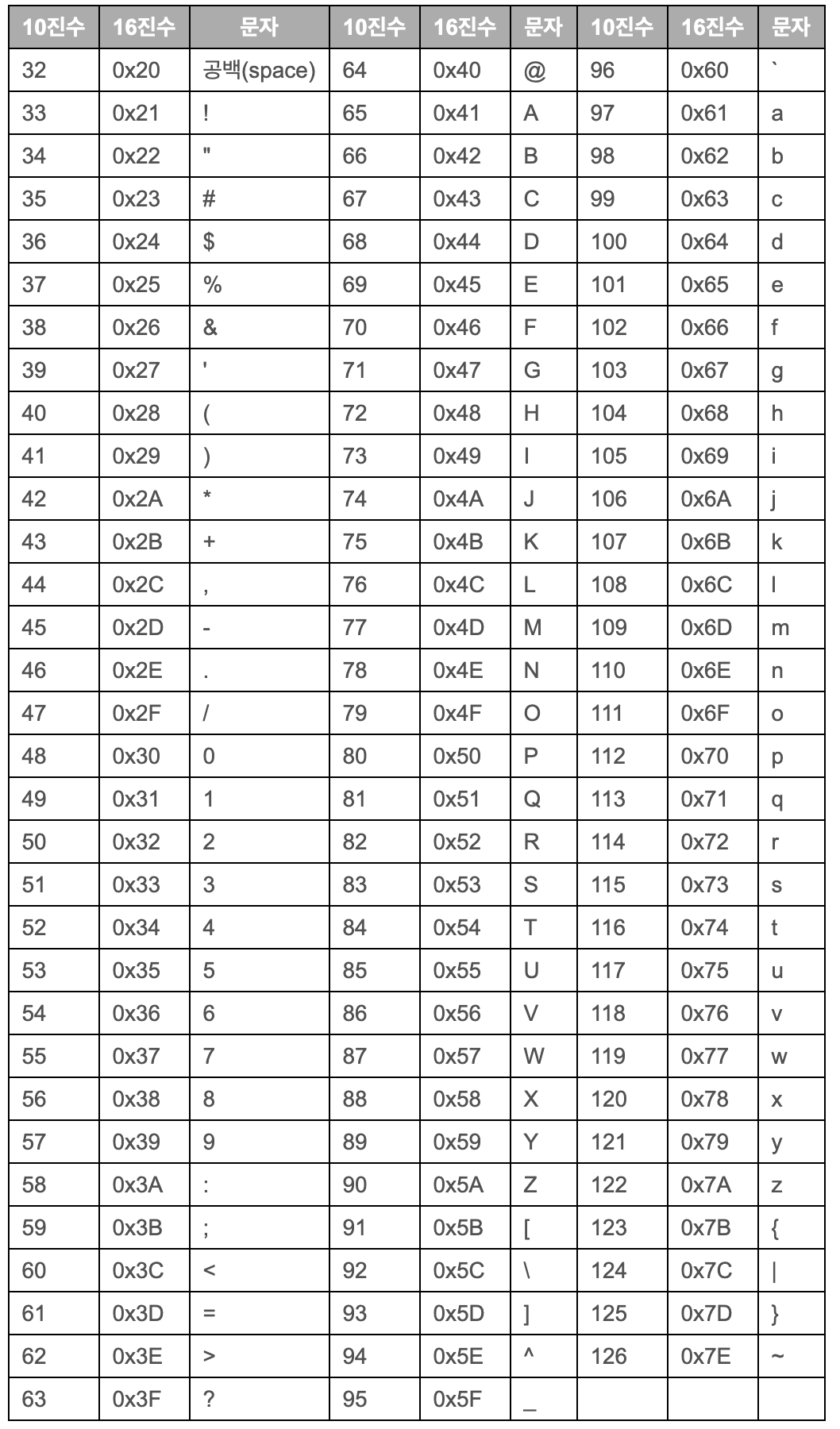
if (c1 == 97) // 문자를 ASCII 코드로 비교
printf("a입니다.\n");
return 0;
}

비교할 변수와 값, 변수와 변수는 자료형을 맞춰줘야 한다. 실수는 연산 한 뒤 반올림 오차가 발생할 수 있으니 이를 감안하여 비교해야 한다. 문자는 위 코드와 같이 문자로 비교해도 되고, 아스키 코드값으로 비교해도 된다.
17.5 사용자가 입력한 값에 if 조건문 사용하기
다음과 같이 scanf 함수를 사용하여 사용자의 입력을 받고 입력 받은 값을 if문으로 비교할 수 있다.
#include <stdio.h>
int main()
{
int num1;
scanf("%d", &num1);
if(num1 == 10)
{
printf("10입니다.\n");
}
if(num1 == 20)
{
printf("20입니다.\n");
}
return 0;
}
조건에 만족하는 것이 있으면 해당하는 코드를 수행하고 만족하는 것이 없으면 아무 코드도 수행하지 않는다.
17.6 퀴즈

정답은 e이다.

정답은 a, c이다.

정답은 b, d이다.
17.7 연습문제 : if조건문 사용하기

c1에 'k'가 저장되어 있으므로 조건을 만족시키려면 정답은 == 'k' 이다.
17.8 심사문제 : 청소년 콘텐츠 관람 제한하기

정답은 다음 코드와 같다.
#include <stdio.h>
int main()
{
int age;
scanf("%d\n", &age);
if(age < 18)
{
printf("청소년 관람 불가\n");
}
return 0;
}
Unit 18. else를 사용하여 두 방향으로 분기하기
if는 분기를 위한 문법이다. 분기는 "둘 이상 갈라지다" 라는 뜻으로 프로그램의 흐름을 둘 이상으로 나누는 것을 말한다.
if에 else를 사용하면 프로그램을 두 방향으로 분기하여 조건식이 만족할 때와 만족하지 않을 때 각각 다른 코드를 실행할 수 있다.
18.1 else 사용하기
else는 if 조건문 뒤에 오며 단독으로 사용할 수는 없다. 사용 형태는 다음과 같다.
if (조건식)
{
코드1
}
else
{
코드2
}#include <stdio.h>
int main()
{
int num1 = 20;
if (num1 == 10)
{
printf("10입니다.\n");
}
else
{
printf("10이 아닙니다.\n");
}
return 0;
}
위 코드에는 num1이 20이라 if 조건식을 만족하지 않기 때문에 else의 코드가 실행되었다.
if 조건식이 만족하면 참(True), 만족하지 않으면 거짓(False)이라고 부르는데, 조건식이 참이면 if의 코드가 실행되고, 거짓이면 else의 코드가 실행된다.
18.2 else와 세미클론
if 처럼 else도 뒤에 세미클론을 붙이지 않도록 주의해야 한다. 세미클론을 붙이면 그 아래 코드는 else와는 관계없는 코드가 되어 버려서 조건식 결과와는 관계 없이 항상 실행되게 된다.
18.3 else에서 중괄호 생략하기
else도 실행할 코드가 한 줄이면 중괄호를 생략할 수 있다.
#include <stdio.h>
int main()
{
int num1 = 20;
if (num1 == 10)
printf("10입니다.\n");
else
printf("10이 아닙니다.\n");
return 0;
}
if, else로 실행할 코드가 두 줄 이상이면 컴파일 에러가 발생한다.
#include <stdio.h>
int main()
{
int num1 = 20;
if (num1 == 10)
printf("1\n");
printf("10입니다.\n");
else
printf("1\n");
printf("10이 아닙니다.\n");
return 0;
}
따라서 두 줄 이상이면 반드시 중괄호로 묶어줘야 한다.
다음과 같이 if만 중괄호로 묶고 else의 코드는 묶지 않았을 경우 컴파일 에러는 발생하지 않지만 조건과 관계없이 두번째 이하의 코드는 항상 실행된다.
#include <stdio.h>
int main()
{
int num1 = 10;
if (num1 == 10)
{
printf("1\n");
printf("10입니다.\n");
}
else
printf("1\n");
printf("10이 아닙니다.\n");
return 0;
}
18.4 if 조건문의 동작 방식 알아보기
if는 0일때 거짓, 0이 아닐때 참으로 동작한다.
#include <stdio.h>
int main()
{
if (5)
printf("참\n");
else
printf("거짓\n");
return 0;
}
조건식에 5를 넣었는데도 참으로 동작한다. 0이아닌 모든 수를 넣으면 참으로 동작하며, 실수도 0.0f가 아닌 값들은 다 참이다.
#include <stdio.h>
int main()
{
if (0)
printf("참\n");
else
printf("거짓\n");
return 0;
}
0은 거짓이기 때문에 위와 같이 else 아래의 코드가 실행되어 거짓이 출력된다.
#include <stdio.h>
int main()
{
int num1 = 5;
if(num1 = 10)
printf("10입니다.\n");
return 0;
}
위 코드에서는 조건식에 =(할당연산자)를 사용하고 있다. 할당 연산자를 사용하게 되면 num1에 10이 할당되어 10이 되고, 10은 0이 아니라 참이기 때문에 if 아래의 코드가 실행된다. 이러한 실수는 컴파일 에러가 발생하지 않아 잡아내기 힘들기 때문에 주의해야 한다. 이런 실수를 줄이기 위해 다음과 같은 코드를 사용하기도 한다.
if (10 == num1)
printf("10입니다.\n");조건식에서 변수를 뒤에 두면 10은 리터럴이기 때문에 값을 저장할 수 없어 만약 =(할당연산자)를 사용하게 되면 컴파일 에러가 발생한다.
18.5 조건식을 여러개 지정하기
if 조건문은 논리연산을 사용하여 조건식을 여러개 지정할 수 있다.
#include <stdio.h>
int main()
{
int num1 = 10;
int num2 = 20;
if (num1 == 10 && num2 == 20)
printf("참\n");
else
printf("거짓\n");
return 0;
}
&&은 논리 연산자이며 "두 식이 모두 만족할 때"를 의미한다. 위 코드에서는 num1이 10인것과 num2가 20인것이 모두 만족하여 참을 출력했다.
이 코드는 다음과 같이 if 조건문 안에 다시 if 조건문을 넣는 구조로도 똑같이 사용할 수 있다.
#include <stdio.h>
int main()
{
int num1 = 10;
int num2 = 20;
if (num1 == 10)
if(num2 == 20)
printf("참\n");
else
printf("거짓\n");
else
printf("거짓\n");
return 0;
}
if 안에 들어와서 다시 if를 만족해야 하므로 &&와 같은 동작을 한다. 안쪽에 있는 if 조건문이 수행할 코드가 한 줄일 경우 위와 같이 바깥쪽과 안쪽의 중괄호를 모두 생략할 수 있다.
18.6 퀴즈

정답은 b이다.

정답은 e이다. 세미클론을 붙이면 안된다.

정답은 거짓이다.

정답은 c,e이다.

정답은 b이다.
18.7 연습문제 : else 사용하기

C에서 0이아니면 모두 참이므로 정답은 0이다.
18.8 연습문제 : 합격 여부 판단하기

정답은 writtenTest >= 80 && toeic >= 850 이다.
18.9 심사문제 : else 사용하기

정답은 다음 코드와 같다.
#include <stdio.h>
int main()
{
char c1;
scanf("%c", &c1);
if(c1 == 'a')
printf("a입니다.\n");
else
printf("a가 아닙니다.\n");
return 0;
}
18.10 심사문제 : 합격 여부 판단하기

정답은 다음 코드와 같다.
#include <stdio.h>
int main()
{
int kor, eng, math, sci, avg;
scanf("%d %d %d %d", &kor, &eng, &math, &sci);
if(kor <= 100 && kor >= 0 && eng <= 100 && eng >= 0 && math <= 100 && math >= 0 && sci <= 100 && sci >= 0)
{
avg = (kor + eng + math + sci) / 4;
if(avg >= 85)
printf("합격\n");
else
printf("불합격\n");
}
else
{
printf("잘못된 점수\n");
}
return 0;
}
Unit 19. else if를 사용하여 여러 방향으로 분기하기
프로그램을 만들다 보면 두 가지 이상의 다양한 상황이 발생하며 이러한 상황들을 처리할 필요가 있다.
else if로 조건식을 여러개 지정하여 각 조건마다 다른 코드를 실행할 수 있다
파이썬에서는 else if 와 동일한 역할을 하는 키워드로 elif를 사용했다.
19.1 else if 사용하기
else if는 else인 상태에서 조건식을 지정할 때 사용하며 단독으로 사용할 수는 없다.
if (조건식)
{
코드1
}
else if (조건식)
{
코드2
}#include <stdio.h>
int main()
{
int num1 = 20;
if (num1 == 10)
printf("10입니다.\n");
else if (num1 == 20)
printf("20입니다.\n");
return 0;
}
위 코드는 num1 이 10인지 검사하여 맞으면 10입니다. 를 출력하고, 거짓이면 그 뒤 else if의 조건식을 검사한다. else의 조건식이 참이면 20입니다.를 출력하고 거짓이면 아무것도 출력하지 않는다. else if에 조건식을 지정하지 않으면 컴파일 에러가 발생한다. else if도 끝에 세미클론을 붙이면 안된다.
19.2 if, else if, else를 모두 사용하기
else if는 else와 함께 사용할 수 있다.
#include <stdio.h>
int main()
{
int num1 = 30;
if (num1 == 10)
printf("10입니다.\n");
else if (num1 == 20)
printf("20입니다.\n");
else
printf("10도 20도 아니다.\n");
return 0;
}
위 코드는 if 조건식과 else if 조건식이 모두 거짓일 때 else의 코드가 실행된다.
if와 else는 한번만 사용할 수 있지만 else if는 여러번 사용할 수 있다.
else if 앞에 else가 오면 컴파일 에러가 발생한다.
19.3 퀴즈

정답은 b,c,e이다.

정답은 e이다. else if에는 조건식이 있어야 한다.
19.4 연습문제 : if, else if, else 모두 사용하기

c가 출력됬으므로 정답은 'c'이다.
19.5 심사문제 : 교통카드 시스템 만들기

정답은 다음 코드와 같다.
if(7 <= age && age <= 12)
balance -= 450;
else if(13 <= age && age <= 18)
balance -= 720;
else
balance -= 1200;
Unit 20. 비교연산자와 삼항 연산자 사용하기
비교연산자는 값을 비교할 때 사용하며 종류는 다음과 같다.
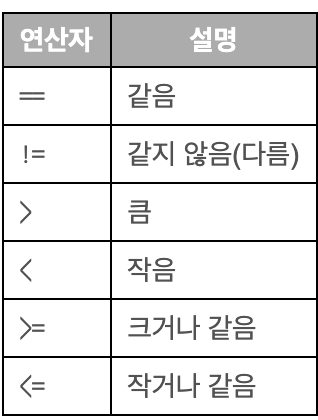
삼항연산자는 연산에 필요한 값이 3개인 연산자이다.

20.1 비교연산자 사용하기
#include <stdio.h>
int main()
{
int num1 = 10;
printf("%d\n", num1 == 10);
printf("%d\n", num1 != 5);
printf("%d\n", num1 > 10);
printf("%d\n", num1 < 10);
printf("%d\n", num1 >= 10);
printf("%d\n", num1 <= 10);
return 0;
}
비교 연산자는 참이면 1, 거짓이면 0이 나온다.
20.2 삼항 연산자 사용하기
삼항연산자는 다음과 같은 형식으로 사용한다.
변수(조건식) ? 값1 : 값2
#include <stdio.h>
int main()
{
int num1 = 5;
int num2;
num2 = num1 ? 100 : 200;
printf("%d\n", num2);
return 0;
}
삼항 연산자는 참, 거짓을 판단할 변수나 조건식을 ? 앞에 지정하고 ? 뒤에 참과 거짓일 때 사용할 값을 나열한다. 각 값은 : 으로 구분하며 앞의 값은 참일때 반환하고, 뒤의 값은 거짓일 때 반환한다.
위 코드에서 num1 은 5로 0이 아니기 때문에 참이므로 : 앞의 값인 100이 num2에 저장되었다.
다음과 같이 비교연산자를 사용한 조건식을 삼항연산자와 함께 사용할 수 있다.
#include <stdio.h>
int main()
{
int num1 = 5;
int num2;
num2 = num1 == 10 ? 100 : 200;
printf("%d\n", num2);
return 0;
}
num1은 5이기 때문에 조건식이 거짓이라 num2 에는 : 뒤의 값인 200이 저장되었다.
삼항연산자는 if 조건문을 짧게 표현할 수 있다는 장점이 있지만, 축약된 형식이기 때문에 가독성을 해칠 수 있다. 가독성을 해치지 않으면서 코드를 간결하게 표현할 수 있을 때만 삼항 연산자를 사용하는 것이 좋다.
20.3 if 조건문과 비교연산자 사용하기
#include <stdio.h>
int main()
{
int num1 = 10;
if (num1 == 10)
printf("10입니다.\n");
if (num1 != 5)
printf("5가 아닙니다.\n");
if (num1 > 10)
printf("10보다 큽니다.\n");
if (num1 < 10)
printf("10보다 작습니다.\n");
if (num1 >= 10)
printf("10보다 크거나 같습니다.\n");
if (num1 <= 10)
printf("10보다 작거나 같습니다.\n");
return 0;
}
비교의 결과가 참이면 if문의 코드가 실행되고, 거짓이면 실행되지 않는다.
다음과 같이 정수 뿐 아니라 실수와 문자도 비교할 수 있다.
#include <stdio.h>
int main()
{
float num1 = 0.1f;
char c1 = 'a';
if (num1 >= 0.09f)
printf("0.09보다 크거나 같습니다.\n");
if (c1 == 'a')
printf("a입니다.\n");
if (c1 == 97)
printf("97입니다.\n");
if (c1 < 'b')
printf("b보다 작습니다.\n");
return 0;
}
문자 자료형도 c1 == 'a'와 같이 문자 그대로 비교할 수 있고, 문자 자료형도 정수이기 때문에 숫자로 비교할 수도 있다.
실수는 반올림 오차가 존재하므로 == 연산자로 정확한 값을 비교하는 것은 위험할 수 도 있다.
20.4 함수 안에서 삼항 연산자 사용하기
#include <stdio.h>
int main()
{
int num1 = 5;
printf("%s\n", num1 == 10 ? "10입니다." : "10이 아닙니다.");
return 0;
}
printf함수로 삼항 연산자의 결과가 출력되고 있다.
위 코드와 같이 삼항연산자는 참/거짓을 판단하여 결과값을 함수에 전달할 때 유용하게 사용할 수 있다.
20.5 퀴즈

정답은 c, d이다.

정답은 c이다.

정답은 d이다.

정답은 c,d 이다.
20.6 연습문제 : 비교 연산자 사용하기

다 참이 나와야 하므로 정답은 >, ==, < 이다.
20.7 연습문제 : 삼항 연산자 사용하기

정답은 >, ?, : 이다.
20.8 심사문제 : 비교 연산자 사용하기

정답은 다음 코드와 같다.
#include <stdio.h>
int main()
{
char c1;
scanf("%c", &c1);
if(c1 != 'k')
printf("참\n");
else
printf("거짓\n");
if(c1 > 'h')
printf("참\n");
else
printf("거짓\n");
if(c1 <= 'o')
printf("참\n");
else
printf("거짓\n");
return 0;
}
20.9 심사문제 : 삼항 연산자 사용하기

정답은 다음 코드와 같다.
num1 != 7 ? 1 : 2
Unit 21. 논리 연산자 사용하기
논리 연산자는 조건식이나 값을 논리적으로 판단한다. 논리값 거짓은 0, 참은 0이 아닌 값이며 보통 1을 많이 사용한다. 다음은 논리 연산자들이다.

21.1 AND 연산자 사용하기
AND연산자는 &&으로 사용한다.
#include <stdio.h>
int main()
{
printf("%d\n", 1 && 1);
printf("%d\n", 1 && 0);
printf("%d\n", 0 && 1);
printf("%d\n", 0 && 0);
printf("%d\n", 2 && 3);
return 0;
}
&&는 두 값이 모두 참이여야 참이 나온다. 따라서 1 && 1만 참이 된다. 또한 C에서는 0이 아닌 값은 모두 참이므로 2 && 3도 참이다.
논리 연산에서 중요한 것은 단락평가이다. 단락평가는 첫번째 값 만으로 결과가 확실할 때 두번째 값은 평가하지 않는 것이다. 0 && 1의 경우 첫번째 값이 거짓이기 때문에 두번째 값은 확인하지 않고 바로 거짓으로 결정한다.
21.2 OR 연산자 사용하기
OR 연산자는 || 으로 사용한다.
#include <stdio.h>
int main()
{
printf("%d\n", 1 || 1);
printf("%d\n", 1 || 0);
printf("%d\n", 0 || 1);
printf("%d\n", 0 || 0);
printf("%d\n", 2 || 3);
return 0;
}
||은 두 값중 하나라도 참이면 결과가 참이다. 따라서 0 || 0만 거짓이다. OR연산은 두 값중 하나만 참이면 참이므로 첫번째 값이 참이면 두 번째 값은 확인하지 않고 참으로 결정한다.
21.3 NOT 연산자 사용하기
NOT 연산자는 ! 으로 사용한다.
#include <stdio.h>
int main()
{
printf("%d\n", !1);
printf("%d\n", !0);
printf("%d\n", !3);
return 0;
}
NOT연산자는 변수, 값, 함수 앞에 !를 붙인다. !은 참은 거짓으로, 거짓은 참으로 논리값을 뒤집는다.
21.4 조건식과 논리 연산자 사용하기
다음과 같이 조건식도 논리연산자로 판단할 수 있다.
#include <stdio.h>
int main()
{
int num1 = 20;
int num2 = 10;
int num3 = 30;
int num4 = 15;
printf("%d\n", num1 > num2 && num3 > num4);
printf("%d\n", num1 > num2 && num3 < num4);
printf("%d\n", num1 > num2 || num3 < num4);
printf("%d\n", num1 < num2 || num3 < num4);
printf("%d\n", !(num1 > num2));
return 0;
}
비교연산자로 대소 관계를 비교한 후 논리연산자로 참, 거짓을 판단하였다.
비교연산자와 논리연산자가 연달아 나오면 알아보기 어렵기 때문에 괄호를 이용하여 알아보기 쉽게 하는 것도 좋다.
printf("%d\n", (num1 > num2) || (num3 < num4)); (age >= 19) && (age < 65)위와 같은 경우 age가 19 미만이면 단락평가로 두 번째 조건은 검사하지 않는다.
21.5 if조건문과 논리 연산자 사용하기
#include <stdio.h>
int main()
{
int num1 = 1;
int num2 = 0;
if (num1 && num2)
printf("참\n");
else
printf("거짓\n");
if (num1 || num2)
printf("참\n");
else
printf("거짓\n");
if (!num1)
printf("참\n");
else
printf("거짓\n");
return 0;
}
각 변수에 1과 0이 들어있으므로 AND연산의 결과는 거짓이고, OR연산의 결과는 참이다.
if 조건문 안에서도 단락 평가를 하기 때문에 num1 || num2의 경우 num1이 1이기 때문에 num2는 검사하지 않고 참으로 결정하여 if의 코드를 실행한다.
int num1 = 0;
int num2 = 10;
if ((num1 != 0) && (num2 / num1) < 20)
printf("참\n");
else
printf("거짓\n");위 코드의 경우 정수를 0으로 나누면 에러가 발생하지만 나눗셈 연산 전에 num != 0으로 num이 0이 아닌지 검사하여 에러를 예방할 수 있다. 단락 평가를 통해 num1이 0이라면 뒤 조건은 검사하지 않고 거짓으로 결정한다.
21.6 삼항연산자에 논리 연산자 사용하기
#include <stdio.h>
int main()
{
int num1 = 1;
int num2 = 0;
printf("%s\n", num1 && num2 ? "참" : "거짓");
printf("%s\n", num1 || num2 ? "참" : "거짓");
return 0;
}
위 코드와 같이 삼항 연산자 안에도 논리 연산자를 사용할 수 있다. num1 은 1이고, num2 는 0이므로 and연산은 거짓이고, or 연산은 참이다.
21.7 퀴즈

정답은 b, d, e이다.

정답은 a, c, e 이다.

정답은 d이다.

정답은 b, c, e이다.
21.8 연습문제 : 논리 연산자 사용하기
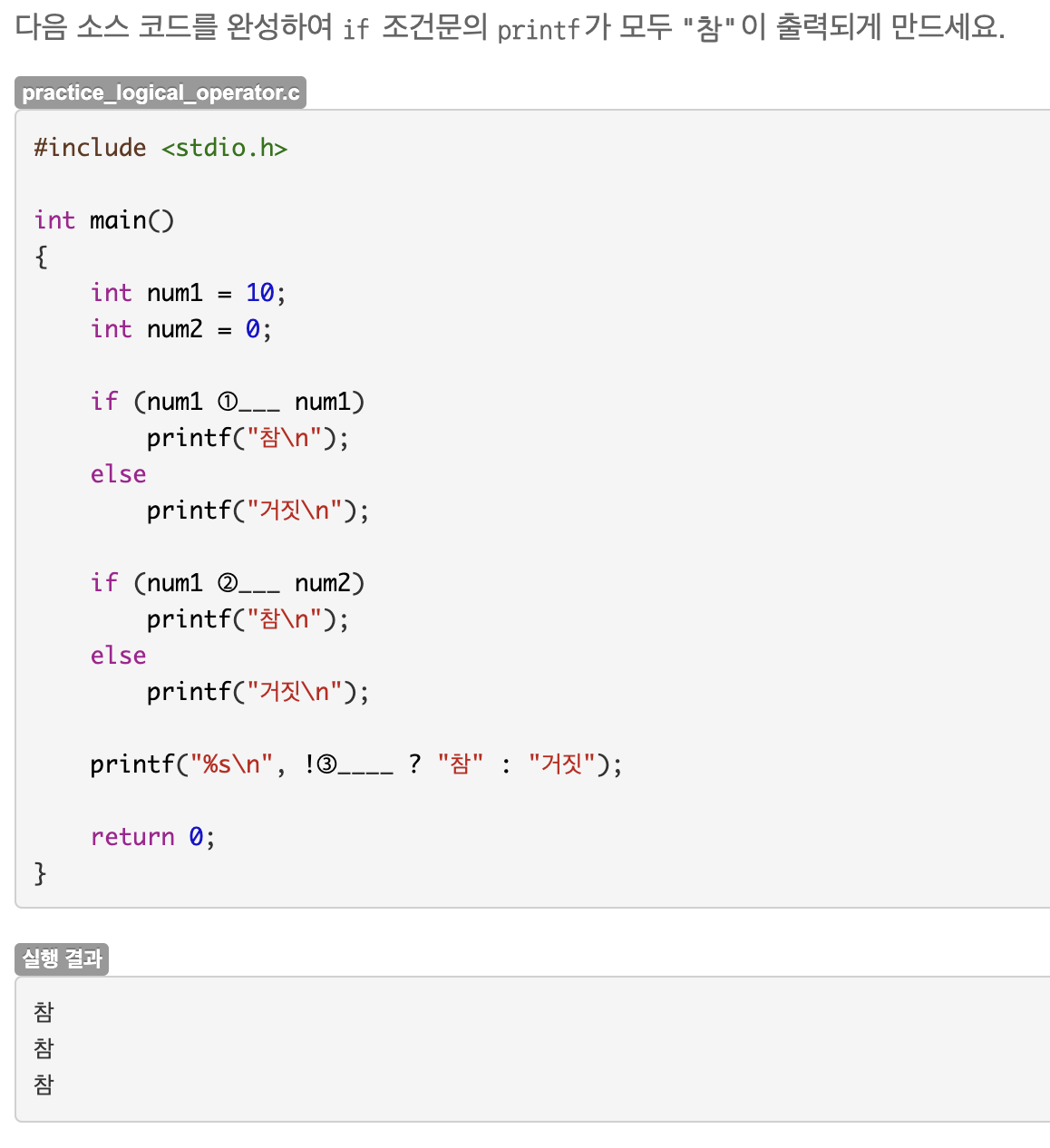
정답은 ||, ||, num2 이다.
21.9 심사문제 : 논리 연산자 사용하기

정답은 다음 코드와 같다.
#include <stdio.h>
int main(void)
{
int n1, n2;
scanf("%d %d", &n1, &n2);
if(n1 && n2)
printf("참\n");
else
printf("거짓\n");
if(n1 || n2)
printf("참\n");
else
printf("거짓\n");
if(!n1)
printf("참\n");
else
printf("거짓\n");
return 0;
}
'Project H4C Study Group' 카테고리의 다른 글
| [Project H4C] C언어 코딩도장(5) (1) | 2021.02.20 |
|---|---|
| [Project H4C] C언어 코딩도장(4) (0) | 2021.02.19 |
| [Project H4C] C언어 코딩도장(2) (0) | 2021.02.17 |
| [Project H4C] C언어 코딩도장(1) (0) | 2021.02.16 |
| [Project H4C] opentutorials HTML(6) (0) | 2021.02.12 |